24 Milliarden gestohlene Datensätze im Umlauf: Ist dein Passwort auch dabei?
Cybernews-Sicherheitsforscher haben eine geleakte Datenbank mit 24 Milliarden Einträgen entdeckt, darunter Benutzernamen, E-Mail-Adressen, unverschlüsselte Passwörter und Login-URLs. Die Daten stammen offenbar aus Infostealer-Malware, infizierten Geräten, Telegram-Kanälen, Breach-Compilations und weiteren Quellen.

Cybernews-Sicherheitsforscher haben eine geleakte Datenbank mit 24 Milliarden Einträgen entdeckt, darunter Benutzernamen, E-Mail-Adressen, unverschlüsselte Passwörter und Login-URLs. Die Daten stammen offenbar aus Infostealer-Malware, infizierten Geräten, Telegram-Kanälen, Breach-Compilations und weiteren Quellen.
- Cybernews-Forscher haben einen offengelegten Elasticsearch-Cluster mit 24 Milliarden Datensätzen und über 8,3 TB Daten entdeckt.
- Der Großteil der Einträge sind offenbar Infostealer-Logs, darunter Benutzernamen, E-Mail-Adressen, Passwörter und Login-URLs.
- Die Daten stammen aus 36 Quellen, darunter Telegram-Kanäle, Breach-Compilations und umfangreiche „Collections“.
- Die Forscher können bislang nicht bestätigen, wie viele Einträge doppelt vorhanden sind und wie viele Personen tatsächlich betroffen sind.
- Die Datenbank ist nicht mehr öffentlich zugänglich, doch wiederverwendete Passwörter können betroffene Konten weiterhin gefährden.
Datenlecks mit Millionen gestohlener Datensätze sind längst zur traurigen Normalität geworden. Doch ein Vorfall mit 24 Milliarden Einträgen, darunter Benutzernamen und Passwörter, ist eine andere Dimension. Kein Wunder also, dass das Cybernews-Forschungsteam seine Ergebnisse mehrfach überprüfte, nachdem es über 8 Terabyte an online offengelegten Daten aufgedeckt hatte.
Am 12. Juni entdeckte unser Team eine der vermutlich größten je offengelegten Datenbanken überhaupt. Der überwiegende Teil der 24 Milliarden Datensätze bestand den Forschern zufolge aus Infostealer-Logs, also gestohlenen Benutzernamen, Passwörtern und den dazugehörigen Diensten, zu denen diese Zugangsdaten Zugang gewähren sollten.
„Das Datenleck ist schlicht aufgrund seines enormen Ausmaßes gefährlich. Da die Daten online zugänglich waren, sind Milliarden betroffener Konten ernsthaft durch Übernahmen gefährdet, besonders wenn sie nicht durch Multi-Faktor-Authentifizierung gesichert sind“, erklärte das Team.
Was enthüllte das Datenleck mit 24 Milliarden Einträgen?
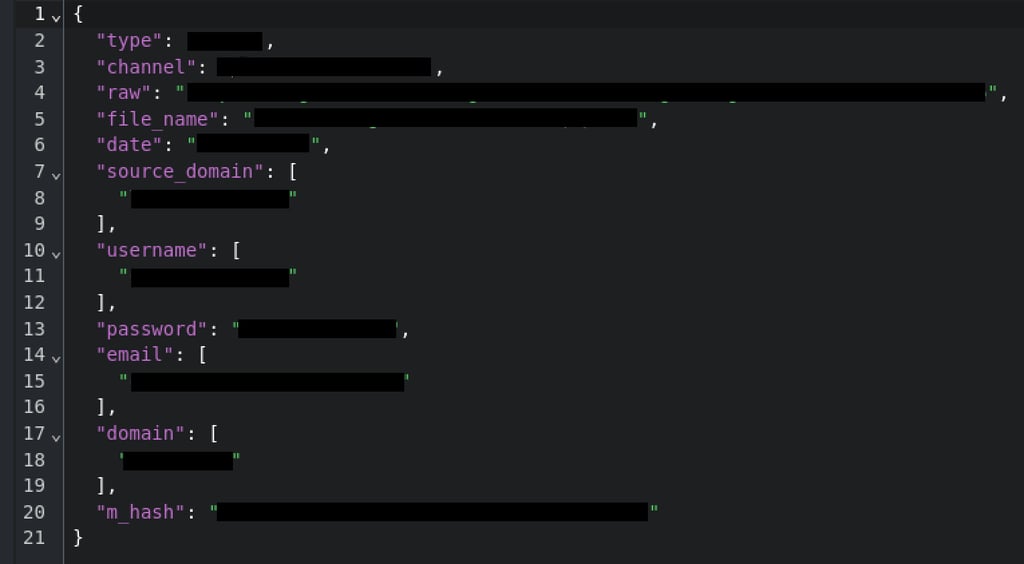
Die von unserem Team aufgedeckten Datensätze waren auf einem öffentlich erreichbaren Elasticsearch-Cluster gespeichert, einem Verbund miteinander verknüpfter Suchserver. Das Gesamtvolumen der im Cluster enthaltenen Informationen überstieg 8,3 Terabyte.
Nahezu alle offengelegten Einträge waren Infostealer-Logs, also Daten, die von Schadsoftware gesammelt wurden, die auf das Stehlen sensibler Informationen ausgerichtet ist. Den Forschern zufolge enthielten die Logs Anmeldedaten im Rohformat, wobei jedes Detail einzeln gespeichert war, darunter E-Mail-Adressen, Benutzernamen und Passwörter im Klartext.
Darüber hinaus identifizierten die Forscher URLs, zu denen die geleakten Zugangsdaten Zugang gewähren sollten, sowie die jeweilige Herkunft der Logs.
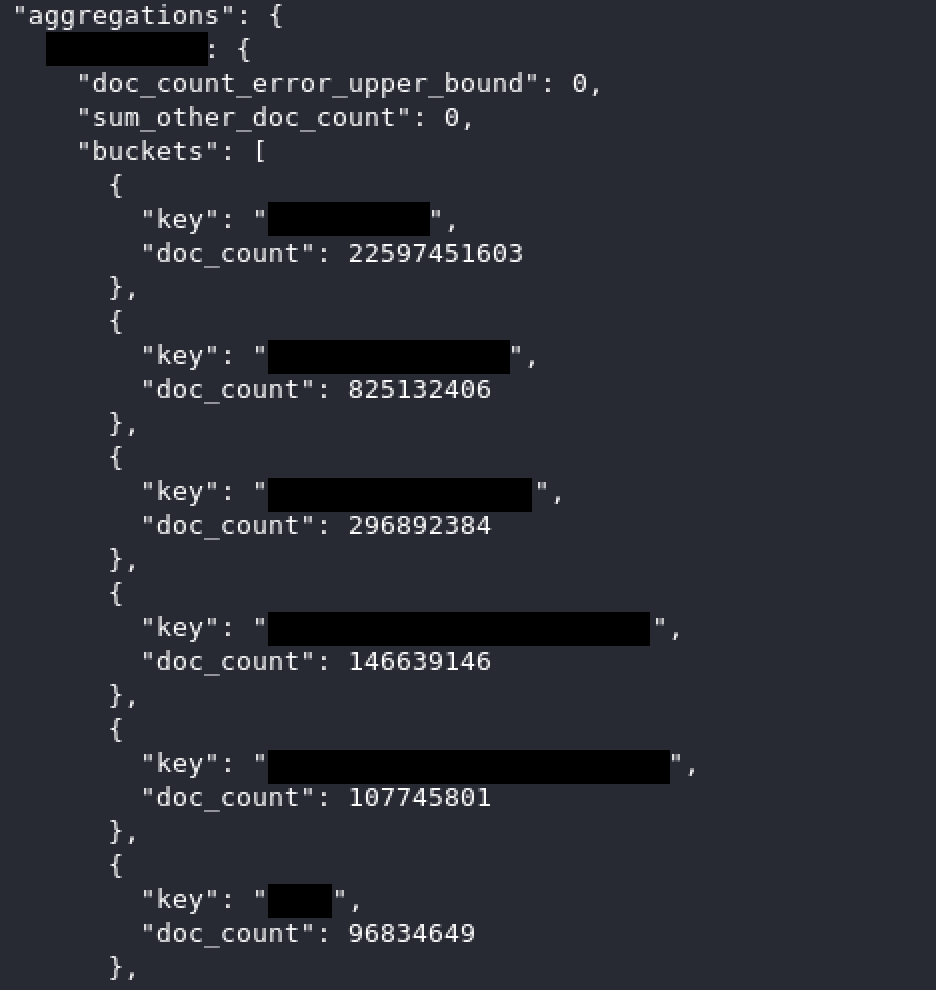
Die offengelegten Zugangsdaten stammten aus 36 verschiedenen Quellen, die von Telegram-Kanälen über kombinierte Sammlungen früherer Datenlecks bis hin zu direkt von aktiven Zielservern exportierten Datensätzen reichten.
Welche Telegram-Kanäle sind in das Datenleck verwickelt?
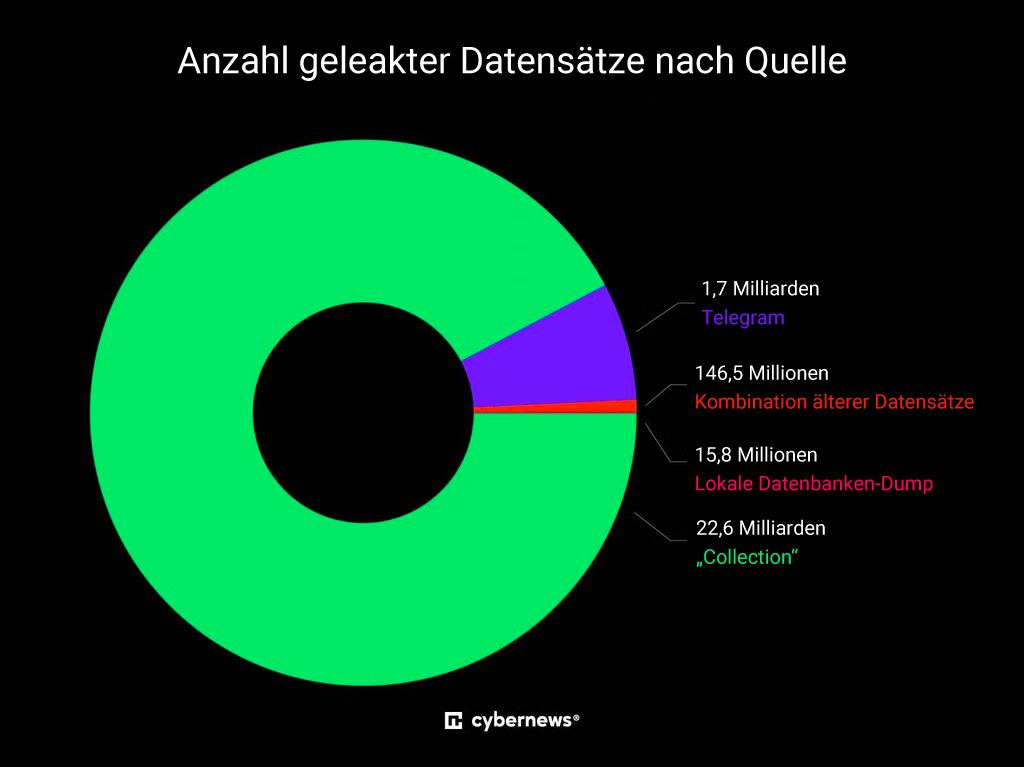
So sollen beispielsweise über 1,7 Milliarden Einträge aus verschiedenen Telegram-Kanälen stammen. Alle Kanäle scheinen in kriminelle Aktivitäten verwickelt zu sein, mit einem klaren Fokus auf gestohlene Zugangsdaten und Datenlecks.
Der Großteil der 36 Datenquellen, mehr als 30, sind Telegram-Kanäle mit Eintragsmengen, die von Hunderten Millionen bis hin zu wenigen Tausend reichen. Die meisten Kanäle waren in englischer Sprache, einige auf Russisch.
Um keine Telegram-Kanäle mit gestohlenen Zugangsdaten zu bewerben, verzichten wir bewusst auf die Nennung ihrer Namen. Der überwiegende Teil der Telegram-Einträge soll jedoch aus Kanälen mit Bezug zu Hackeraktivitäten stammen.
Eine weitere Kategorie umfasst Telegram-Kanäle, die Zugang zu gestohlenen Kreditkartendaten gewähren, darunter offenbar ein Kanal, der ganz diesem Zweck gewidmet ist.
Bemerkenswert: Knapp 260 Millionen Einträge stammen aus Telegram-Kanälen, die „Darkside“ im Namen tragen. Darkside war vor einigen Jahren eine der aktivsten Ransomware-Gruppen überhaupt. Die Bande griff seinerzeit die Colonial Pipeline an und löste damit massive Kraftstoffversorgungsengpässe an der US-Ostküste aus.
Milliarden von Einträgen in unbekannten „Collections“
Ganze 22,6 Milliarden Einträge sollen aus dem stammen, was der Dateneigner als „Collections“ bezeichnete. Diese Einträge könnten aus verschiedenen Infostealer-Sammlungen stammen, die bereits zuvor online aufgetaucht sind, oder sie deuten darauf hin, dass die Daten nach den Diensten gruppiert wurden, zu denen sie unbefugten Zugang ermöglichen sollen.
Da die Daten kurz nach ihrer Entdeckung aus dem öffentlichen Zugriff genommen wurden, konnten unsere Forscher die Herkunft der Informationen innerhalb der sogenannten „Collection“-Quelle nicht weiter untersuchen.
Aus demselben Grund war es dem Team nicht möglich, genau zu ermitteln, welche Dienstanbieter betroffen sind. Angesichts der enormen Datenmenge liegt es jedoch nahe, dass die Zugangsdaten Diensten mit sehr großen Nutzerbasen zuzuordnen sind.
Zudem fiel dem Team eine Quelle mit 150 Millionen Einträgen auf, die als „Local Database Dumps“ bezeichnet wurde. Die Einträge aus dieser Quelle wurden offenbar direkt von aktiven Zielservern exportiert. Bei lokalen Datenbank-Dumps handelt es sich typischerweise um das Herunterladen des Inhalts einer bestimmten Datenbank auf ein Benutzergerät.
Check if your data has been leaked
Im konkreten Fall könnten „Local Data Dumps“ bedeuten, dass die Person, die den Server betrieb, die Einträge selbst in die Sammlung hochgeladen hat, oder dass sie die Daten aus anderen Quellen bezogen hat.
„Zudem enthielten die Einträge Dateinamen, aus denen sie importiert wurden. Insgesamt gab es mindestens 195 verschiedene Dateinamen. Einige davon deuteten darauf hin, dass die betreffenden Zugangsdaten aus der AntiPublic-Collection stammen und zeigten, um welche Art von Konten es sich dabei handelt“, berichteten unsere Forscher.
Die AntiPublic-Collection ist eine Stealer-Log-Combo-Liste, die erstmals 2016 auftauchte und rund 600 Millionen Einträge umfasste. Die AntiPublic-bezogenen Informationen im Leck kategorisierten die enthaltenen Zugangsdaten: Einige Dateien enthielten ausschließlich Logins für Dienste mit Inhalten für Erwachsene, andere wiederum nur Zugangsdaten für Streaming-Plattformen.
Weitere 146 Millionen Einträge stammten aus einer Quelle mit der Bezeichnung „Breach Compilation Combo“ und enthalten höchstwahrscheinlich Informationen aus früheren Datenlecks, bei denen Zugangsdaten von Nutzern kompromittiert wurden. Angreifer nutzen gezielt Informationen aus vergangenen Sicherheitsvorfällen, da Nutzer häufig dieselben Zugangsdaten wiederverwenden und Passwörter selten ändern.
Die Quelle mit den wenigsten Einträgen trug den Namen „Redline Stealer“ und enthielt lediglich 27 Datensätze. RedLine Stealer ist ein weit verbreiteter Infostealer, der als Malware-as-a-Service (MaaS) betrieben wird und es auch technisch weniger versierten Angreifern ermöglicht, an Cyberkriminalität teilzunehmen.
Dateneigner verfolgt Nachrichtenartikel und Social-Media-Beiträge
Interessanterweise fanden unsere Forscher eine kleine Teilmenge von rund 17.000 Einträgen, die Informationen enthielt, die in Datenlecks nur selten auftauchen. So enthielten über 9.500 Dokumente CVE-IDs (Common Vulnerabilities and Exposures) und zugehörige Beschreibungen sowie entsprechende GitHub-Repository-URLs.
Eine der im offengelegten Cluster identifizierten Sicherheitslücken betraf einen Fehler im Valhall-GPU-Kernel-Treiber.
Darüber hinaus enthielten über 5.200 Dokumente Verlaufsdaten aus Nachrichtenartikeln zu aktuellen Datenlecks, inklusive Artikel-URLs, Inhalten und Kurzbeschreibungen. Einer der Artikel wurde noch im Februar 2026 veröffentlicht und behandelte einen Lieferkettenangriff auf das Python Package Index (PyPI)-Repository.
Weitere rund 2.900 Dokumente waren Protokolle von Social-Media-Beiträgen zu Cybersicherheitsvorfällen. Einer der vom Team gesichteten Beiträge diskutierte technische Details der Babuk-Ransomware aus dem Jahr 2021.
All das deutet darauf hin, dass der Dateneigner die Cybersicherheitslandschaft aktiv beobachtet, vermutlich mit der Absicht, seine umfangreiche Zugangsdatensammlung laufend mit Einträgen aus den neuesten Datenlecks zu ergänzen.
Was wir (noch) nicht wissen
Wir sind zwar überzeugt, dass das von unserem Team aufgedeckte Datenleck tatsächlich 24 Milliarden Einträge umfasst, doch gibt es Grenzen dessen, was wir über die Inhalte des inzwischen geschlossenen Elasticsearch-Clusters wissen.
Das Team hatte nur begrenzt Zeit, das Datenleck zu untersuchen, was eine tiefergehende Analyse der in der „Collections“-Quelle enthaltenen Informationen verhinderte.
Zudem lässt sich nicht zuverlässig einschätzen, wie viele Duplikate im Leck enthalten sind, sodass die tatsächliche Zahl betroffener Personen offen bleibt. Es wäre allerdings kaum überraschend, wenn ein Datenleck mit 24 Milliarden Einträgen weit mehr als nur einige wenige Online-Konten beträfe.
Derzeit lässt sich auch nicht zuverlässig sagen, wie alt oder neu die geleakten Daten sind. Anhand des im Datenleck enthaltenen Nachrichtenartikels vom Februar 2026 scheint der Dateneigner den Cluster regelmäßig mit neuen Informationen zu aktualisieren.
Wir wissen auch nicht, wer hinter dem Datenleck steckt oder warum jemand derart große Datenmengen horten würde. Unser Team ist der Ansicht, dass „sowohl ein Unternehmen als auch ein einzelner Bedrohungsakteur solche Informationen aus verschiedenen Gründen sammeln könnte“.
„Unternehmen könnten diese Daten für einen Überwachungs- oder Sicherheitsprüfdienst erheben, während Bedrohungsakteure sie nutzen könnten, um neue Angriffsvektoren zu finden und Datenlecks zu begünstigen“, erklärten unsere Forscher.
Unser Team ist zudem der Überzeugung, dass beim Umgang mit historischen Datenlecks gilt: Je mehr, desto besser.
„Warum sollte man nicht so viele Daten horten? Bei historisch geleakten Daten und Informationen zu Exploits und Angriffen gilt: Je mehr Informationen man hat, desto besser, da dies tiefere Einblicke ermöglicht, die Erkennung kompromittierter Konten verbessert und aufzeigt, auf welche Weise ein bestimmtes Ziel angegriffen werden könnte“, erläuterte das Team.
Was kannst du jetzt tun, um deine Daten zu schützen?
Um sicher zu bleiben, ist Eigeninitiative gefragt, denn ein paar einfache, aber wirkungsvolle Maßnahmen können viel bewirken. Wer dasselbe Passwort für mehrere Dienste verwendet, sollte es so schnell wie möglich ändern, angefangen bei wichtigen Konten wie E-Mail, sozialen Netzwerken, Cloud-Speicher und Online-Banking.
Empfehlenswert ist außerdem, die Multi-Faktor-Authentifizierung überall dort zu aktivieren, wo sie verfügbar ist, und einen Passwort-Manager zu nutzen, um starke und einzigartige Passwörter zu erstellen. Zudem solltest du auf Phishing-Nachrichten achten, die in manchen Fällen vorgeben, dabei helfen zu können, herauszufinden, ob deine Daten kompromittiert wurden.
Mit ein paar guten Angewohnheiten und den richtigen Tools kann man seine Privatsphäre wirksam schützen und erschwert Angreifern erheblich, an personenbezogene Daten zu gelangen.
- Nutze stets ein VPN, wenn du öffentliche WLANs nutzt. Es schützt deine Verbindung und hält sie privat.
- Vorsicht beim Anklicken von Links oder Öffnen von Anhängen aus E-Mails oder Nachrichten, denen du nicht vertraust.
- Aktualisiere Apps und Betriebssysteme auf allen Geräten, denn Updates enthalten häufig wichtige Sicherheitspatches.
- Aktiviere die Zwei-Faktor-Authentifizierung (2FA), wann immer sie verfügbar ist, für eine zusätzliche Sicherheitsebene.
- Lade Apps und Software ausschließlich aus offiziellen Stores oder vertrauenswürdigen Quellen herunter, um gefälschte oder infizierte Versionen zu vermeiden.
Strong password generator

Milliardenlecks werden zur Normalität
Leider werden Datensätze mit Milliarden von Einträgen immer häufiger geleakt. Vor ziemlich genau einem Jahr entdeckte unser Team 4 Milliarden Datensätze aus chinesischen Chat-Apps, darunter Ausweisnummern, Telefonnummern und Benutzernamen.
Zu Beginn dieses Jahres fanden die Cybernews-Sicherheitsforscher ein Datenleck internationaler Social-Media-Konten, bei dem insgesamt 149 Millionen Nutzerkonten betroffen waren.
Im Juli 2025 deckte Cybernews eines der größten Datenlecks der Geschichte auf, als mehrere Sammlungen von Anmeldedaten mit insgesamt 16 Milliarden Einträgen entdeckt wurden. Das Team fand 30 offengelegte Datensätze, die jeweils zwischen Dutzenden Millionen und über 3,5 Milliarden Einträgen enthielten.
Die genannten Beispiele sind jedoch wesentlich kleiner als das aktuelle Datenleck. Der einzige Vorfall, der mit der aktuellen Entdeckung vergleichbar ist, fand unser Team bereits 2024. Dieses gigantische Leck bündelte Daten aus zahlreichen früheren Sicherheitsvorfällen und umfasste 12 Terabyte an Informationen, verteilt auf über 26 Milliarden Einträge.
Ablauf der Offenlegung:
- Leck entdeckt: 12. Juni 2026
- Leck geschlossen: 15. Juni 2026
Entdecke weitere exklusive Cybernews-Reportagen auf YouTube.