Cloudflare wasn't breached, but that's little comfort
Just like Microsoft Azure and Amazon Web Services outages, the incident at Cloudflare impacted millions of customers and once again showed that we might be putting too many of our eggs in too few baskets.

Image by Cybernews.
Just like Microsoft Azure and Amazon Web Services outages, the incident at Cloudflare impacted millions of customers and once again showed that we might be putting too many of our eggs in too few baskets.
- The web's dependence on a handful of providers (Cloudflare, AWS, Azure) creates dangerous single points of failure where one outage can paralyze millions of businesses globally.
- While major providers offer low costs and accessible security tools, the hidden price is extreme vulnerability when these platforms fail, even briefly.
- Organizations must adopt multi-provider strategies, failover systems, and comprehensive contingency planning to break dependency chains before a malicious attack causes irreversible damage.
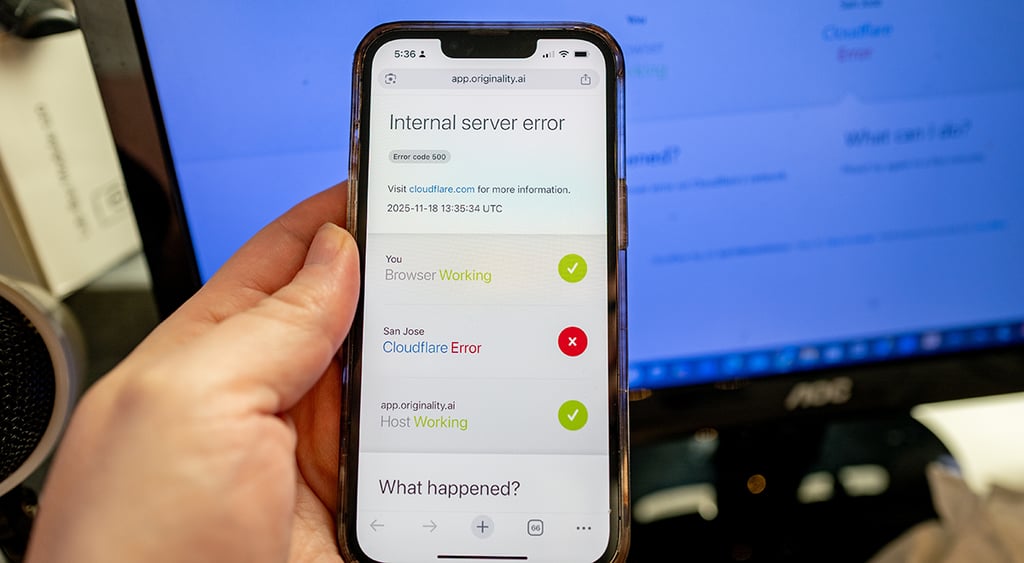
Cloudflare has more or less recovered from an hours-long outage on Tuesday and assured customers that the incident wasn’t related to any sort of malicious activity. The company’s founder, Matthew Prince, also apologized.
However, at this point, the specific cause of the incident isn’t exactly the issue. The problem is that these outages are still so painful to businesses and their customers.
The pattern – and the pain – persists because most organizations haven’t yet realized how exposed they are on the web if they depend on giant service providers.




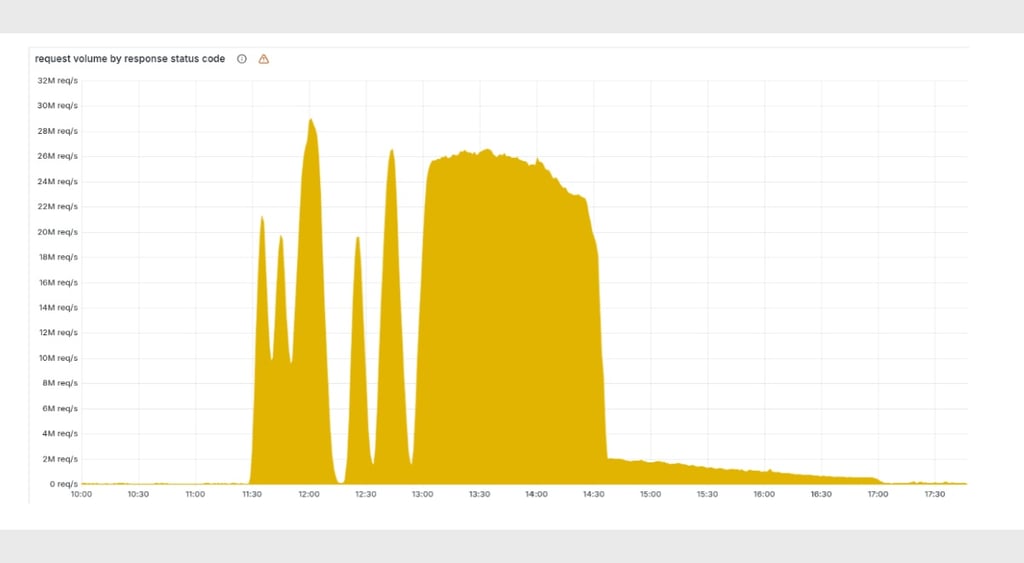
The trade is actually kind of obvious: costs are low, and security tools are more accessible. However, when a platform of this size slips (even for a few hours), the impact spreads immediately – like it did on Tuesday when Cloudflare screwed up – and leaves us wondering how a single outage can shut down a huge chunk of the global web.
Costs are low, but the risk is high
Cloudflare is, of course, one of the world’s largest network providers, serving nearly 300,000 customers operating in 125 countries, including China. It acts as an intermediary to ensure websites remain online, can manage high volumes of traffic, and fend off DDoS attacks.
Unsurprisingly, when the error messages began appearing – just like when Azure and AWS went down – millions of frustrated business customers and individual users saw them.
“Cloudflare going down sits in the same pattern we saw with the recent AWS and Azure outages. These platforms are vast, efficient, and used by almost every part of modern life,” said Graeme Stewart, head of public sector at Check Point Software.
“The upside is obvious. Their scale keeps costs low, makes security tools more accessible, and gives even small organizations the kind of performance that would once have been impossible. The downside is just as clear. When a platform of this size slips, the impact spreads far and fast, and everyone feels it at once.”
Indeed, all these incidents underscore the vulnerabilities associated with reliance on a small number of service providers. In other words, it’s not just about inconvenience: it’s about systemic risk.
On the one hand, it can feel great that we’re all so interconnected, but maybe, just maybe, the modern web is too tightly interwoven if disruptions on one major provider have such cascading global effects.
“Centralization of hosting companies has led to a deferral of blame for SaaS companies – they can say ‘well, AWS is down!’ and feel abdicated of responsibility for the downtime they provide to customers. We need to decentralize hosting infrastructure to avoid this,” Tom Bachant, CEO and founder of Unthread, told Cybernews.
Likewise, to Rob Demain, CEO at cybersecurity firm e2e-assure, the Cloudflare outage “is a reminder of how fragile our digital systems can be and how much we rely on just a few key players to keep the internet running smoothly.”
How to prevent outages: Diversify and reduce dependency
According to Bachant, outages seem increasingly impactful these days, but companies aren’t investing in preventing them. One way to do that is to at least try to break the so-called dependency chain.
As Demain explains, services like Cloudflare are designed with strict uptime guarantees and are never supposed to go offline, but in reality, of course, this is not the case. The solution? Having alternatives at hand.
“Cloudflare is designed to ensure business continuity, yet outages like this result in quite the opposite, with no backup or alternative when things go wrong. It's not very easy to have two content delivery network providers, though organisations may now look into this,” said Demain.
When we have one single large vendor, however excellent its services are, we put all eggs in one basket, eventually creating a single point of failure. If lawmakers and regulators do nothing following this incident, we will be basically sitting down and asking for a disaster,Dr. Ilia Kolochenko.
Jano Bermudes, Chief Operations Officer at global cybersecurity consultancy CyXcel, concurs, saying that the outage is another reminder of the dangers of centralization.
“Organizations must go beyond basic resilience measures and rethink dependency models by adopting multi-region architectures, robust failover strategies, and comprehensive contingency planning,” said Bermudes.
“Multi-cloud strategies can help reduce reliance on a single provider and mitigate systemic risk. It’s not a silver bullet, but when implemented with clear governance and interoperability standards, it can significantly strengthen resilience without adding unnecessary risk.”
Dr. Ilia Kolochenko, CEO of ImmuniWeb and a fellow of the British Computer Society, believes we’re facing extreme systemic risk and need to “urgently ensure” that all business-critical web services are provided by at least several vendors of a comparable size and with a similar market share.

“Otherwise, when we have one single large vendor, however excellent its services are, we put all eggs in one basket, eventually creating a single point of failure. If lawmakers and regulators do nothing following this incident, we will be basically sitting down and asking for a disaster,” said Kolochenko.
Pending global disaster
He also sees a cybersecurity risk and offers a scenario in which several state-backed cybercrime groups one day decide to cause long-lasting damage to Cloudflare or another systemic vendor by breaking into its networks and destroying all accessible data and backups.
“This may lead to a global disaster. Given how companies and governments on both sides of the Atlantic are dependent on the internet, we may expect a total paralysis and the eventual collapse of the economy,” said Kolochenko.
That’s why increasing cyber resilience right now seems crucial to most experts who realize that reducing dependency on centralized infrastructure won’t happen overnight.
Many organizations experienced downtime on Tuesday because their dependency on Cloudflare was absolute, with no fallback path for DNS resolution, distributed content, or authentication.
“Organizations focus heavily on defending against malicious threats, but sometimes overlook resilience against operational failures, misconfigurations, or service provider outages. But cyber resilience is as much about preparing for failures as it is about preventing them,” wrote Ken Underhill, a cybersecurity professional.
He explained that many organizations experienced downtime on Tuesday because their dependency on Cloudflare was absolute, with no fallback path for DNS resolution, distributed content, or authentication.
Establishing redundant DNS providers, multi-CDN (content delivery network) strategies, or hybrid cloud approaches can help ensure that single points of failure do not cascade into business-critical outages, Underhill said.
Similarly, organizations should maintain updated incident response plans that include playbooks for provider disruptions, including clear procedures for traffic rerouting, throttling, or activating static fallback sites when primary systems fail.
For now, though, outages are here to stay. And it’s getting hotter – let’s not forget what happened to CrowdStrike last year when an outage caused a global IT meltdown.
“We now have AWS, Azure, and Cloudflare outages in the span of a month,” David Choffnes, a professor of computer science at Northeastern University, told The New York Times.
“Companies have had outages before, but they tend to be pretty rare. These companies are supposed to be really, really good at keeping things up.”
Unlock more exclusive Cybernews content on YouTube: