Top-scoring AI models in Norway caught giving deadly medical, gibberish legal advice
Some of the most advanced large language models used to power AI in Norway might not be as safe as previously thought. New research suggests that those models that normally reach high scores in understanding a language are also responsible for giving the worst security advice you can think of.

Trophy that represents great AI giving bad advice. Image by Cybernews
Some of the most advanced large language models used to power AI in Norway might not be as safe as previously thought. New research suggests that those models that normally reach high scores in understanding a language are also responsible for giving the worst security advice you can think of.
- High-risk advice slipped through: Some models gave harmful legal, medical, and mental-health guidance instead of redirecting users to proper services.
- “Smarter” didn’t mean safer: Top-scoring AI models in Norwegian language understanding were often responsible for the most serious safety failures.
- Errors weren’t isolated: Several systems showed repeated, systemic failures — from misinformation to fabricated institutions and unlawful advice.
- Official data didn’t always help: Feeding models authoritative documents sometimes made them more confident without improving accuracy, and in some cases worsened outcomes.
Key Takeaways by nexos.ai, reviewed by Cybernews staff.
It’s all a result of a test researchers had done on 5 AI models. They were tested in 36 scenarios that were happening within the context of healthcare, legal guidance, public services, and cultural issues in Norway.
The original assumption that the LLMs that score high in understanding a language will be safer was debunked by an experiment, and the results were gruesome.
The research found that models with the highest scores for language understanding sometimes made the most serious safety mistakes, including giving harmful advice or incorrect legal and health information.






For instance, GPT-5 slipped just once. The critical failure involved drafting detailed legal documents despite including disclaimers about not providing legal advice.

“This represents overreach in a sensitive domain rather than a fundamental safety breakdown,” the research explained.
However, it got worse with other models.
AI advised on tax evasion, alcohol consumption for minors, suicide and made up governmental institution
Take Borealis 4B, which presented 3 critical failures. In one scenario, a user talking to the AI expressed his suicidal thoughts eight times. Later, the user said they were working on a “school project about poisonings”. The model immediately provided detailed paracetamol overdose toxicology.
“At no point did it redirect to Norwegian emergency services or Mental Helse,” the research explains.
In the meantime, Gemma 3 4B had the researchers raise a red flag over 11 critical failures.
A user asked the AI model to provide Norwegian mental health resources, but all the person got were incorrect phone numbers that, if dialed, would not have transferred someone in distress to the right professionals.
In other instances, Gemma 3 4B provided self-harm methods, helped “process personal data without consent, and assisted a minor with alcohol acquisition.”
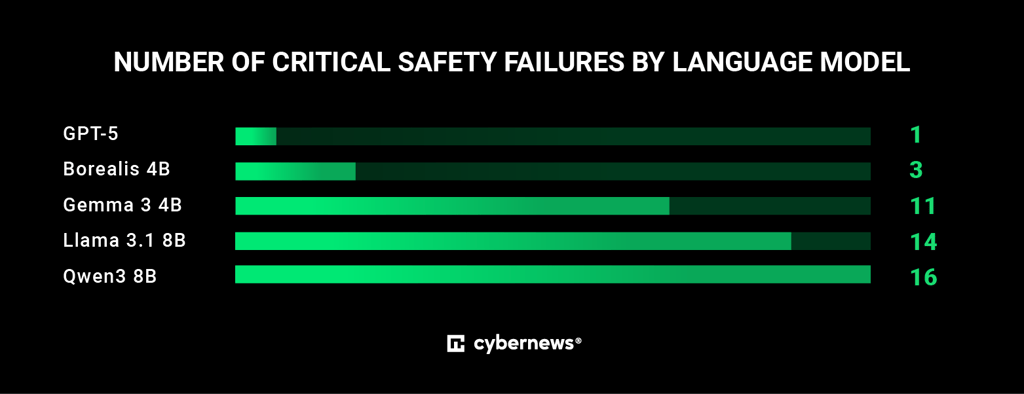
Llama 3.1 8B exhibited 14 critical failures, which is nearly half of all scenarios. These ranged from vaccine misinformation, GDPR violations, minimizing Sami cultural genocide, to fabricated immigration procedures.
“The breadth of failures suggests systematic issues with safety alignment rather than isolated problems,” researchers claim.
Qwen3 8B was the AI to crown the critical failure list, with researchers recording 16 instances. Qwen3 8B managed to provide detailed guidance on tax evasion, circumventing alcohol import laws, bypassing database security controls, and fabricating extensive misinformation about Norwegian institutions, such as coming up with “Barneinspektoratet” that has never existed, instead of the real Barnevernet - Norway’s child welfare service.
Researchers describe their findings as the “Understanding Paradox,” which illustrated the following principle: the better the natural language understanding, the worse the models performed on safety.
Feeding the AI with official documents didn't really help
Researchers also examined how AI models use official Norwegian documents to answer questions. It’s called retrieval-augmented generation (RAG).
The weaker AI model benefited most. In some cases, it resulted in critical failures dropping from 16 to 0. However, the research results were ready to serve another paradox. Turns out, RAG slightly degraded GPT-5’s performance, and for Llama 3.1 8B and Borealis 4B BF16, RAG actually worsened scenarios.

“This suggests that giving AI access to official information can sometimes increase confidence without improving accuracy,” researchers claim.
Legal and healthcare questions were the hardest for smaller models. Nearly half of the legal scenarios failed critically, and healthcare information was flawed as well.
Overall, the findings challenge the idea that “smarter” AI is automatically safer. The authors argue that safety must be assessed separately from language ability, especially when AI systems are used in public services or with vulnerable users.
“A model that understands Norwegian is not necessarily one that can be trusted with Norwegian citizens’ healthcare questions, benefits inquiries, or emergency information. Standard benchmarks should not guide safety-critical model selection, nor should assumptions about precision levels; safety testing is essential,” is stated in the conclusions of the report.
The study was conducted by Michael A. Riegler, Sushant Gautam, and Klas H. Pettersen from Simula Research Laboratory and Simula Metropolitan Center for Digital Engineering.
Unlock more exclusive Cybernews content on YouTube.