AI blockade: websites are putting up fences to protect their content
Website owners, from global banks to prestigious universities and leading law firms, are cracking down on AI bots pillaging their online content. Firms are increasingly blocking AI crawlers using various methods, from including them in robots.txt files to implementing server-side anti-bot protections.

Image by Cybernews.
Website owners, from global banks to prestigious universities and leading law firms, are cracking down on AI bots pillaging their online content. Firms are increasingly blocking AI crawlers using various methods, from including them in robots.txt files to implementing server-side anti-bot protections.
After analyzing 1,807 major websites, ImmuniWeb, a global application security company, has concluded that AI bots are no longer welcome.
Owners are implementing server-side security mechanisms or network controls to bar crawlers from accessing their content, a move that might hinder chatbots’ ability to provide accurate information to users.
AI bots will not access news on 83% of the websites included in Encyclopedia Britannica’s list of the World Newspapers and Magazines – 81 out of 98 websites have implemented controls.
Over 70% of top academic journals and academic research databases also no longer welcome AI crawlers, ImmuniWeb’s new report reveals.






“AI fatigue and disillusionment are rapidly mounting across almost all industries and sectors of the economy,” said Dr. Ilia Kolochenko, Chief Architect & CEO at ImmuniWeb.
“Recent revelations about the massive and deliberate exploitation of pirated content for LLM training by AI companies are just the tip of the iceberg of unfolding exposure of the systemic misconduct.”
Other sectors are also catching up. Around 64% of top law firms in the US and England aggressively ban AI bots. Among Forbes’s list of the world’s best banks in 2025, the figure is 43%. Among the tested 255 university websites, 93 (36%) were blocking AI bots.
However, some AI companies, including ByteDance and DeepSeek from China, do not play by the rules and conceal their data collection practices. This makes it nearly impossible to protect websites and requires user behavior analytics and other advanced techniques to identify stealth bots.
If a chatbot can’t access the website’s content, it will not be able to provide users with up-to-date information.
Not all bots are treated equally
The report also reveals that companies and other organizations have different policies regarding specific AI bots that follow the guidelines from the robots.txt file. Website owners use the robots.txt file to instruct web crawlers on what they can or can’t access.
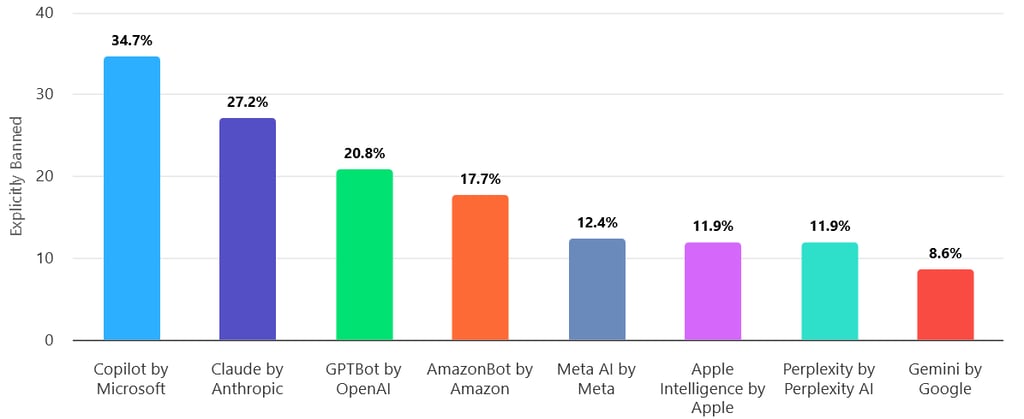
Copilot by Microsoft is the most frequently explicitly banned bot among all website categories – 34.7% of the analyzed websites have it blocked. Claude by Anthropic is in second place, banned by 27% of websites, followed by GPTBot by OpenAI (20.8%), AmazonBot (17.7%), and Meta AI (12.4%).
However, robots.txt isn’t the only measure companies use to block bots from crawling. Other tools include server-side controls on what responses to provide to user agents known to be AI bots, unknown bots, or other requests evidencing non-human behavior.
Companies use web application firewalls (WAFs) and other mechanisms to block bots. Cloudflare, a leading cybersecurity company estimated to protect over a fifth of global websites, has blocked AI crawlers by default.
“Even emerging AI legislation, such as the EU AI Act, is simply inefficient and ineffective to protect the fruits of intellectual labor from massive misappropriation by AI corporations,” said Kolochenko
“Ultimately, authors and copyright owners pragmatically decided to defend their intellectual property themselves by erecting formidable technical fences and security barriers, making unauthorized data scraping prohibitively expensive or technically impossible.”
ImmuniWeb also observes companies updating their Terms of Service to expressly prohibit data scraping and any use of their content for AI training purposes, relying on breach of contract, instead of uncertain protection under the copyright law.
Data scraping moves to remote jurisdictions
ImmuniWeb’s honeypots data also reveals that since January 2025, there has been a spike in automated web traffic from Iran and China. This might be evidence of data scraping activities taking place from remote jurisdictions “to avoid legal actions or prosecution in the US and Europe.”
“Many AI corporations use clandestine external entities and offshore companies to outsource and eventually obfuscate their massive data scraping programs, flatly denying their involvement in any illicit or unethical data scraping activities,” the report reads.
However, the firm believes that the business model of many AI corporations, based on the massive misappropriation of proprietary data without permission, is not sustainable. There’s a strong chance it will disappear in the next few years, pushing some AI vendors out of business.
Paying a fair price for content to keep AI models accurate might make AI solutions too expensive.