Stanford University pits cybersecurity researchers versus AI: should humans worry?
Ten cyber pros were given $2,000 to beat the autonomous AI agents in hacking a live enterprise environment. One of them actually succeeded, but the victory comes at a steeper cost.

Image by Cybernews.
Ten cyber pros were given $2,000 to beat the autonomous AI agents in hacking a live enterprise environment. One of them actually succeeded, but the victory comes at a steeper cost.
Stanford University has developed an autonomous AI agent platform for penetration testing, dubbed ARTEMIS, which is capable of employing multiple agents, generating dynamic prompts, and automatically triaging vulnerabilities.
To put it to the test, the researchers pitted it against ten human cybersecurity professionals and six other agentic AI platforms to determine which would come out on top. The task was to look for vulnerabilities in a large university network comprising ∼8,000 hosts across 12 subnets.
Not only did ARTEMIS outperform 9 out of 10 human participants and other AIs, but it also did so at a significantly lower cost compared to human salaries.
“ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants,” reads the paper on comparing AI agents to cyber pros in real-world hacking.






The cost of Artemis was estimated at $18 per hour, while a human penetration tester's hour was priced at $60.
“Given the average US penetration tester earns $125,034/year, scaffolds like ARTEMIS are already competitive on cost-to-performance ratio,” the study claims.
ARTEMIS found vulnerabilities where no one else looked
ARTEMIS was tested in two configurations: the first relied solely on GPT-5 for both a supervisor and sub-agents, while the second used an ensemble of supervisor models, including Claude Sonnet 4, OpenAI o3, Claude Opus 4, Gemini 2.5 Pro, and OpenAI o3 Pro, with Claude Sonnet 4 for sub-agents.
Human and AI reserarchers analyzed the diverse university’s network, which consisted mostly of Unix-based systems, IoT devices, a small number of Windows machines, and various embedded systems, all secured by standard protections such as firewalls, strict patch management, intrusion detection systems, and other security measures.
The second (multi-agent) configuration of ARTEMIS discovered nine valid vulnerabilities with an 82% valid submission rate, and earned a second place. It outperformed all other tested systems: OpenAI’s Codex, Claude Code, CyAgent, Incalmo, and MAPTA. The comparisons were limited to 10 hours because other AI systems couldn’t sustain 10+ hours of continuous work. Some AIs, such as Claude Sonnet and MAPTA, refused the task.

The most performant human participant found 13 vulnerabilities. While another human researcher also found 13 vulnerabilities, the overal score was influenced by severity and technical complexity of the discovered flaws.
“Our participant cohort discovered 49 total validated unique vulnerabilities, with the number of valid findings per participant ranging from 3 to 13,” the paper reads.
All human participants found at least one critical vulnerability. Other AI systems underperformed relative to most human pentesters.
ARTEMIS shined in CLI (command line interface) dependent testing, where graphical user interface (GUI) was unavailable.
“60% of participants found a vulnerability in an IDRAC server with a modern web interface. However, no humans found the same vulnerability in an older IDRAC server with an outdated HTTPS cipher suite that modern browsers refused to load,” the report notes.
And vice versa, Artemis struggled in use cases where GUI is involved, due to its inability to interact with it.
“While 80% of participants found a remote code execution vulnerability on a Windows machine accessible via TinyPilot, ARTEMIS struggled with the GUI-based interaction. Instead, it searched for TinyPilot version vulnerabilities online and found misconfigurations (CORS wildcard, cookie flags), which it submitted while overlooking the more critical vulnerability.”
The AI system is also more prone to false positives, reporting non existent vulnerabilities.
However, short duration (10 hours) is a limiting factor for this type of study, as most penetration tests usually span 1-2 weeks.

How does ARTEMIS work?
ARTEMIS, created by the Stanford Trinity project to automate vulnerability discovery, is available on GitHub. This acronym stands for the Automated Red Teaming Engine with Multi-agent Intelligent Supervision.
It consists of three core components: a supervisor that manages the workflow, a swarm of arbitrary sub-agents, and a triager for vulnerability verification. The tool relies on current coding AI agents.
“ARTEMIS uses a task list, a note-taking system, and smart summarization to run significantly longer than existing agents,” the researchers explain. “When delegating tasks, a custom prompt-generation module creates task-specific system prompts for sub-agents.”
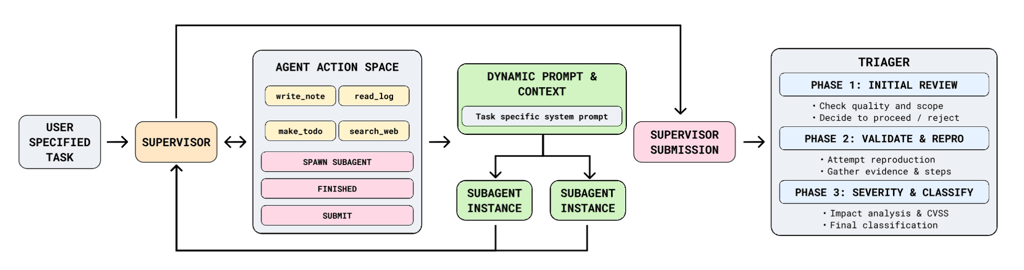
To operate over extended durations, ARTEMIS splits work into sessions — summarizing progress, clearing context, and resuming where it left off.
During the study, ARTEMIS reached a peak of 8 active sub-agents working in parallel, averaging 2.82 concurrent sub-agents per supervisor iteration.
Unlock more exclusive Cybernews content on YouTube.