US AI giants face trillion-dollar dilemma as cheaper Chinese models take two of top five positions
DeepSeek is now more than twice as intelligent as it was when it was first released a year ago. While the new model is still slightly behind the best from Google, Anthropic, or OpenAI, it will complete the same job at least 22 times cheaper.

Image by Cybernews.
DeepSeek is now more than twice as intelligent as it was when it was first released a year ago. While the new model is still slightly behind the best from Google, Anthropic, or OpenAI, it will complete the same job at least 22 times cheaper.
In January, DeepSeek, a relatively small AI studio based in China, disrupted the industry by releasing a free-weight model that demonstrated ChatGPT-like capabilities.
Despite billions of dollars spent on advances and multiple subsequent model releases from top AI firms in the US, which have been leapfrogging one another, the race remains neck and neck.
Here are the current standings of the most capable AI models from different firms across various benchmarks, according to Artificial Analysis, an independent AI benchmarking and analysis company from San Francisco.
- Gemini 3 Pro from Google (US) – 73%
- Claude Opus 4.5 from Anthropic (US) – 70%
- GPT-5.1 from OpenAI (US) – 70%
- Kimi K2 Thinking from Moonshot AI (China) – 67%
- DeepSeek V3.2 (China) – 66%
- Grok 4 from xAI (US) – 65%
- MiniMax-M2 (China) – 61%
- Qwen3 235B from Alibaba Cloud (China) – 57%
- GLM-4.6 from Z.ai (China) – 56%
- Mistral Medium 1.2 from Mistral (France) – 52%




Meta, with its Llama offerings, is no longer among the top 10 AI studios.
The Artificial Analysis Index is calculated as a weighted average of the models’ performance across several difficult benchmarks. However, it doesn’t compare how effective the AI models are in crunching the tokens.
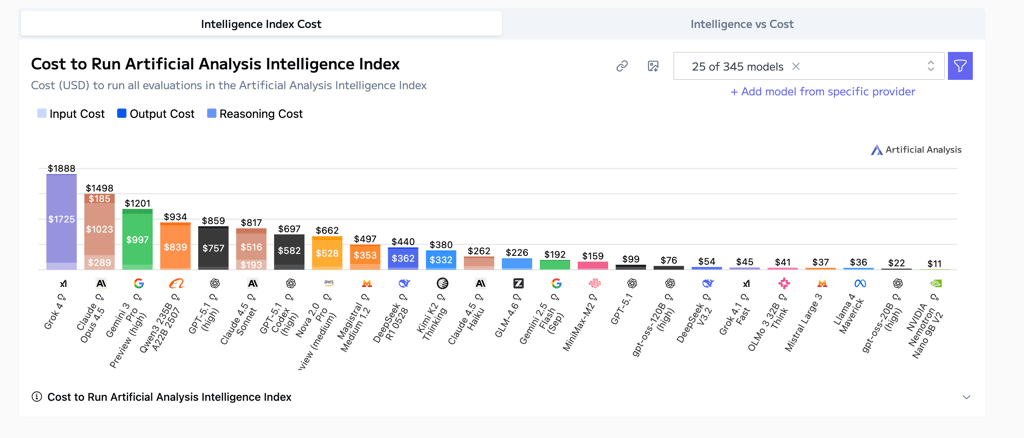
In this metric, open-weight Chinese models slay any competition. Here are the prices to complete the same task – to run all the evaluations in the aforementioned Artificial Analysis Intelligence index.
- $54 – DeepSeek V3.2
- $159 – MiniMax-M2
- $226 – GLM-4.6
- $380 – Kimi K2 Thinking
- $497 – Magistral Medium 1.2
- $859 – GPT-5.1
- $934 – Qwen3 235B
- $1,201 – Gemini 3 Pro
- $1,498 – Claude Opus 4.5
- $1,888 – Grok 4
How can DeepSeek be so shockingly cheap?
DeepSeek announced its new V3.2 models on Monday, with a post on X that’s already generated 4.4 million views. The firm selected some tests where the model beats even a Gemini 3 Pro, currently the best model.
DeepSeek V3.2 is more than twice as intelligent as the R1 model released at the beginning of the year, which caught the industry off guard.
Yet, the model remains the same size, with 671 billion total parameters and 37 billion active parameters. AI enthusiasts had been running DeepSeek AI models on single Mac computers, albeit in a quantized form (lower precision and size).
The studio made numerous optimization decisions to minimize the model’s runtime costs.
It cites three key “breakthrough” technologies: “DeepSeek Sparse Attention” (DSA), which reduces computational complexity, “Scalable Reinforcement Learning Framework,” which scales post-training compute, and “Large-Scale Agentic Task Synthesis Pipeline,” which generates synthetic training data when using tools to facilitate agentic post-training.
“Our Long Context Reasoning benchmark showed no cost to intelligence of the introduction of DSA,” Artificial Analysis said in a post on X.
“DeepSeek reflected this cost advantage of V3.2-Exp by cutting pricing on their first-party API from $0.56/$1.68 to $0.28/$0.42 per 1M input/output tokens – a 50% and 75% reduction in pricing of input and output tokens, respectively.”
DeepSeek released two flavors of the newest V3.2 models – one tailored for tool use, and another, called Speciale, specialized for reasoning tasks, but without tool calling support.
Many tech pros on the Y Combinator’s Hacker News forum acknowledged DeepSeek’s win in cost efficiency. However, there are trust issues due to the geopolitical situation and potential compliance issues.
Cheap open-weight models from China are undercutting revenue perspectives for big tech companies.
Already, IBM CEO Arvind Krishna argues that major big tech companies, which are pouring trillions into AI-focused data center expansion, may not recoup their investments.
“It’s my view that there’s no way you’re going to get a return on that because $8 trillion of CapEx means you need roughly $800 billion of profit just to pay for the interest,” Krishna said on the Decoder podcast.
Is overtaking Gemini 3 in sight?
The startup seems to understand why it still lags behind Gemini 3.0 or other frontier closed-source models. The paper mentions three reasons.
“First, due to fewer total training FLOPs, the breadth of world knowledge in DeepSeek-V3.2 still lags behind that of leading proprietary models. We plan to address this knowledge gap in future iterations by scaling up the pre-training compute,” the paper reads.
Have thoughts about this topic? Others do, too. Join them in the discussion.
The Chinese firm has limited access to the most advanced semiconductor chips.
Token efficiency remains the second challenge, as DeepSeek typically requires more tokens to achieve the same output quality as models like Gemini 3 Pro. In the future, the startup plans to optimize “the intelligence density” in reasoning.
“Third, solving complex tasks is still inferior to frontier models, motivating us to further refine our foundation model and post-training recipe,” DeepSeek researchers concluded.
Unlock exclusive Cybernews content on YouTube.