Perplexity ignores no-crawl directives and scrapes websites anyway, Cloudflare warns
The AI-powered search engine Perplexity breaks trust by ignoring websites’ no-crawl directives and even masquerades as other users to bypass network blockers, a report by Cloudflare has found.

Image by Cybernews.
The AI-powered search engine Perplexity breaks trust by ignoring websites’ no-crawl directives and even masquerades as other users to bypass network blockers, a report by Cloudflare has found.
Perplexity’s bots repeatedly modify their user agent, change their source origin to hide crawling activity, and ignore – or sometimes don’t even fetch – robots.txt files.
Robots.txt is a standardized set of instructions for websites to indicate to visiting web crawlers what they can or can’t access. While it can’t enforce the rules and is built on trust, most legitimate tech companies respect this sort of “Code of Conduct” sign.
Cloudflare said it has delisted Perplexity as a verified bot and added heuristics to block stealthy crawling.
“There are clear preferences that crawlers should be transparent, serve a clear purpose, perform a specific activity, and, most importantly, follow website directives and preferences,” the tech firm explains.






The researchers started investigating Perplexity’s crawling activity after receiving complaints from customers, who had attempted to block unwanted crawling but found that Perplexity was still able to access their content.
“We created multiple brand-new domains, similar to testexample.com and secretexample.com. These domains were newly purchased and had not yet been indexed by any search engine nor made publicly accessible in any discoverable way,” Cloudflare explains.
The robots.txt files were adjusted with simple directives to stop any bots from accessing any part of a website.
However, when querying Perplexity AI search with questions about these domains, it provided detailed information scraped from them.
“This response was unexpected,” the report reads.
The researchers went further and adjusted web application firewall (WAF) rules to filter out Perplexity’s bots, effectively blocking them. Then the bots changed the declared user-agent to a generic Google Chrome browser on macOS to bypass the block.
“This undeclared crawler utilized multiple IPs not listed in Perplexity’s official IP range, and would rotate through these IPs in response to the restrictive robots.txt policy and block from Cloudflare.”
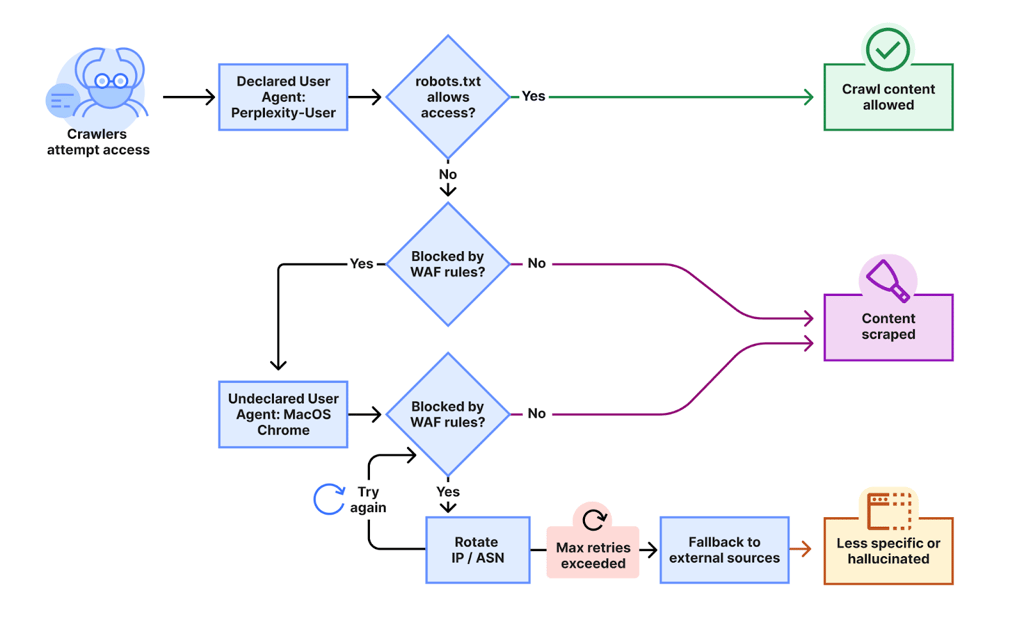
Even when the stealth crawlers were successfully blocked, Perplexity was observed using other data sources, including other websites, to create answers about the domains. However, the answers were less specific and lacked details about the original content.
Unwanted bot crawling activity can lead to increased server load, data leaks, and loss of ad revenue when users get the information directly from the AI assistant. Disregarding robots.txt may constitute a violation of the terms of service.
“OpenAI is an example of a leading AI company that follows these best practices. They clearly outline their crawlers and give detailed explanations for each crawler’s purpose. They respect robots.txt and do not try to evade either a robots.txt directive or a network-level block,” Cloudflare said.
Cloudflare believes that content creators and publishers should have more control over their content and how it is accessed. Over 2.5 million websites – the firm’s customers – have now chosen to completely disallow AI training through a managed robots.txt feature or rule.
The industry is working to standardize extensions to robots.txt to establish clear and measurable principles for bots.