A tiny AI just beat GPT‑4o‑mini at Doom
It has 1.3 million parameters and runs on a laptop CPU, yet outguns models up to 92,000 times its size.
DOOM Videogame Tournament. Jonathan Leibson/Getty Images/Bethesda Softworks.
It has 1.3 million parameters and runs on a laptop CPU, yet outguns models up to 92,000 times its size.
Big AI companies are releasing increasingly large models – including Claude Mythos, the latest massive model that has wowed the world. But small can also be mighty, as those tinkering with local LLMs are learning.
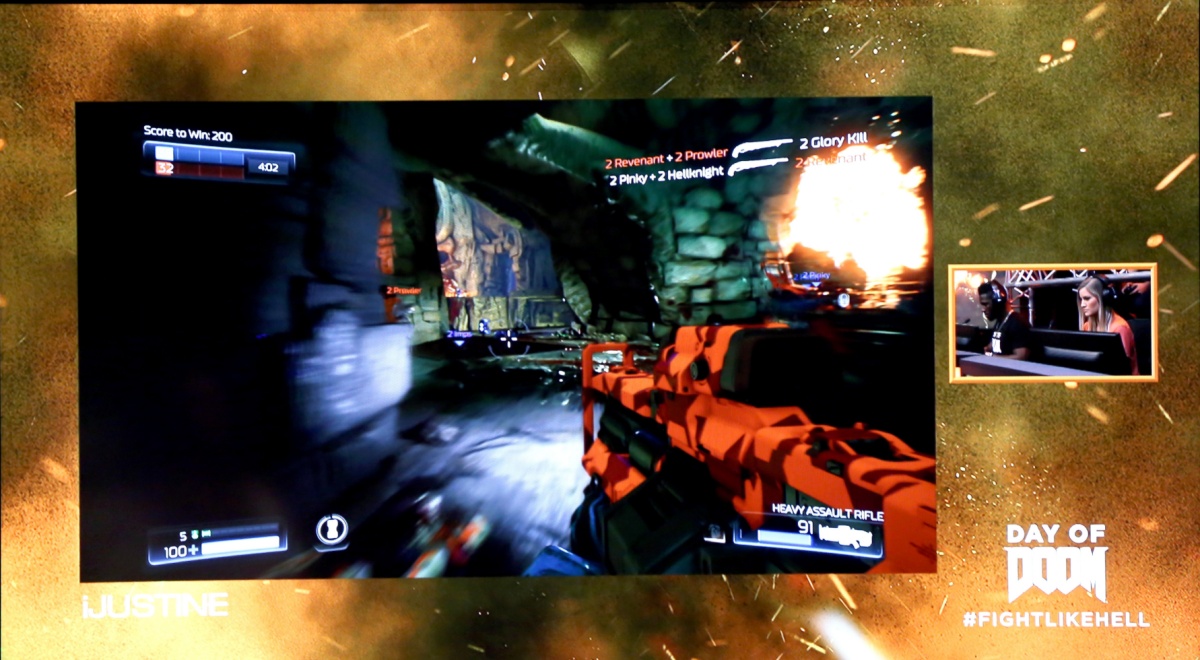
In the defend_the_center arena of the 1993 first‑person shooter Doom, enemies close in from every direction, and a player has seconds to turn, aim, and fire. It’s the sort of thing that the largest, most capable artificial intelligence models on the market should excel at.
Instead, a 1.3‑million‑parameter model called SauerkrautLM‑Doom‑MultiVec has beaten them all – including some models more than 92,000 times its size.






That gap in size and success is the headline finding of a paper published on the arXiv preprint server by David Golchinfar of VAGO Solutions in Germany, alongside colleagues at the University of Applied Sciences Bonn‑Rhein‑Sieg and Japan’s Nara Institute of Science and Technology.
Across 10 in‑game episodes, their small model scored 178 frags, compared to just three for Nemotron‑120B, which, true to its name, has 120 billion parameters. The 27-billion parameter Qwen3.5‑27B model scored just two, while GPT‑4o‑mini scored zero.
Big numbers, little action
Every large language model the researchers tested is multimodal and could, in principle, process raw game screenshots. But in the tests, each model received the same compressed ASCII‑and‑depth‑map representation as the others, to keep the comparison fair. Despite this, the larger models struggled.
GPT‑4o‑mini survived longer than most, managing around 104 steps on average, but only by spinning on the spot to avoid being seen, never firing a shot. The small model was the only agent that actively engaged enemies rather than evading them.

Speed is a large part of the story behind the smaller model’s success. Doom runs at 35 frames per second, which gives an agent roughly 28 milliseconds to decide what to do next. SauerkrautLM‑Doom‑MultiVec makes its decision in 31ms on a CPU.
Nemotron‑120B takes 8.9 seconds – a long enough period for an in‑game enemy to cross the entire arena and begin attacking before the model has replied. Even the fastest large language model in the benchmark, GPT‑4o‑mini, is roughly 21 times too slow.
Research by Mark Claypool and Kajal Claypool in the mid‑2000s found player accuracy in first‑person shooters drops 35% at just 100ms of lag; every LLM here blew through that budget by between six and 133 times.
Training for success
What makes the performance of the smaller model all the more impressive is that training amounted to only two hours of a human playing Doom in “spectator mode”, producing 31,000 labelled frames.
Check if your data has been leaked
The success of small, task‑specific models being able to decisively outperform general‑purpose giants at real‑time control is one that a growing chorus of researchers has been driving for months.
Peter Belcak and colleagues at Nvidia argued in June 2025 that small language models are the future of agentic AI, citing potential cost savings of 10 to 30 times. The Doom result is a particularly vivid demonstration of this principle: running the tiny model costs nothing, and at just 5MB, it could sit on a Raspberry Pi Zero 2W.
While we’re increasingly concerned with edge deployment, real‑time control, and per‑query cost, a model small enough to run on a single‑board computer just outscored a 120‑billion‑parameter system by 58 frags to one.
It all suggests that there is a new route for people to take if they want to pick the right AI model for their task – and sometimes the right answer is not to scale up.
Unlock more exclusive Cybernews content on YouTube.