This AI model with just 15B parameters reaches DeepSeek R1 levels of intelligence
An unexpected contender has appeared in the top AI model leaderboards. With just 15 billion parameters, Apriel-1.5-15B-Thinker can run on a single GPU, is open-weight, and demonstrates capabilities similar to DeepSeek R1, Google Gemini 2.5 Flash, or other LLMs that are 10x larger.

An unexpected contender has appeared in the top AI model leaderboards. With just 15 billion parameters, Apriel-1.5-15B-Thinker can run on a single GPU, is open-weight, and demonstrates capabilities similar to DeepSeek R1, Google Gemini 2.5 Flash, or other LLMs that are 10x larger.
Artificial Analysis, an independent AI benchmarking firm, recently highlighted this small model’s high scores across multiple industry benchmarks.
Apriel-1.5-15B-Thinker demonstrates frontier-level reasoning while running almost for free. It’s open weights, meaning anyone can run it unrestricted on their own machine, and it can fit on a single GPU.
It correctly answered 71.3% of the questions written by experts in biology, physics, and chemistry (GPQA). It’s very strong in math, with 87.5% accuracy in AIME 2025 (2025 American Invitational Mathematics Examination). It also scored 72.8% in the coding benchmark LiveCodeBench.




The model scored particularly well in instruction following, tool use, and other agentic tasks.
Apriel is now the most intelligent across all small models below 40 billion parameters, as measured by Artificial Analysis.
SLAM Lab, a small team of researchers from ServiceNow, a cloud-based workflow automation company, developed the model. They claim that Apriel matches DeepSeek-R1-0528, a massive 45-times larger 671 billion parameter model.
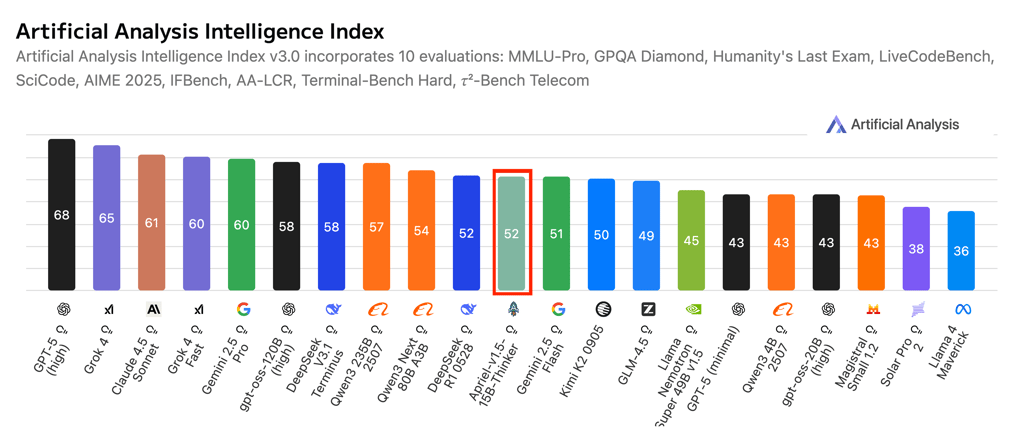
“On the Artificial Analysis Intelligence Index, Apriel-1.5-15B-Thinker attains a score of 52, matching DeepSeek-R1-0528 despite requiring significantly fewer computational resources, the paper reads.
For comparison, the highest-scoring frontier model, GPT-5 Codex (high), currently has a score of 68% in the same evaluation. Meanwhile, Grok 4 has 65%, Claude 4.5 Sonnet, 63%, and Gemini 2.5 Pro 60%.
“Across ten image benchmarks, its performance is on average within five points of Gemini-2.5-Flash and Claude Sonnet-3.7, a key achievement for a model operating within single-GPU deployment constraints.”
How did they achieve this? The researchers explain that training design was more important than the sheer scale.
They improved another AI model from Mistral, Pixtral-12B, in three stages. The researchers made the model a bit bigger by adding more layers to boost its reasoning power. They continued the model’s pretraining, developing foundational reasoning, broad multimodal capabilities, and, later, visual reasoning.
In the third stage – supervised fine-tuning – the model was trained using a curated “diverse, high-quality, and high-signal set of samples.”

Notably, our model achieves competitive results without reinforcement learning or preference optimization,” the paper reads.
The team wanted to create a compact, open, and multimodal model that is economical to train and deploy. Companies often require on-premises or air-gapped deployments for privacy and compliance, which can operate within strict hardware constraints.
“It is at least 1/10 the size of any other model that scores > 50 on the Artificial Analysis index,” the team claims on Hugging Face, where the model was made available for free.
The model in the original 16-bit quantization requires 29.7GB of VRAM to fit in one GPU. This leaves only a single consumer GPU capable of running it: Nvidia’s RTX 5090. Dual GPU setups might be more cost-effective. However, already quantized versions are available, lowering the memory demands, but also sacrificing some precision.
The researchers also said they used 640 H100 GPUs, running for seven days, for training. Nvidia said that around a quarter of the Apriel-v1.5's pre-training text data for depth up-scaling came from the Nvidia Nemotron collection.
“We are a small lab with big goals. While we are not GPU poor, our lab, in comparison, has a tiny fraction of the compute available to other Frontier labs. Our goal with this work is to show that a state-of-the-art model can be built with limited resources if you have the right data, design, and solid methodology,” the researchers’ post reads.
Unlock more exclusive Cybernews content on YouTube.