Chinese startup MiniMax drops an AI model that can shake industry profit margins
A Chinese startup has just dropped an AI bombshell – an open large language model (LLM) that challenges proprietary chatbots’ business models. MiniMax-M2 ranks among the global top five, beating Gemini or DeepSeek, while being cheap to run with only 10B active parameters.

Image by Cybernews.
A Chinese startup has just dropped an AI bombshell – an open large language model (LLM) that challenges proprietary chatbots’ business models. MiniMax-M2 ranks among the global top five, beating Gemini or DeepSeek, while being cheap to run with only 10B active parameters.
As proprietary AI models seem to be slowing in advancement, the industry is sprawling with new open-weight models that are closing the gap with ever-increasing efficiency.
MiniMax-M2 is the latest AI model tailored for coding, agents, and tool use.
The team behind it claims that it will generate tokens nearly as good as Claude Sonnet 4.5, the best AI model from Anthropic. But MiniMax-M2 will cost only 8% and be twice as fast. It’s open-weight, which means that anyone can adapt it to run on their own hardware.




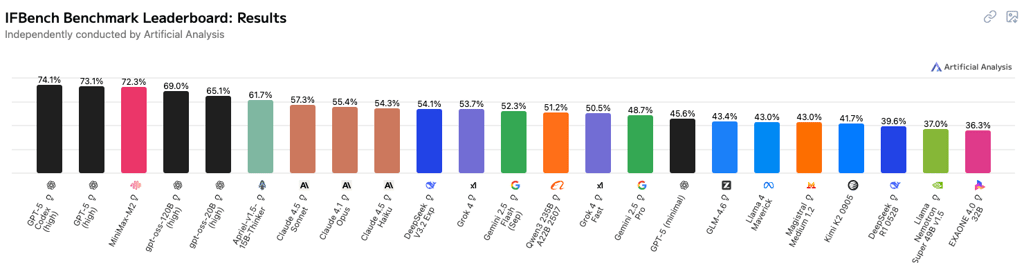
According to the third-party benchmarks from Artificial Analysis, Minimax-M2 is currently the most intelligent open weights model, ranking in the global top five.
With an average intelligence index of 61%, it demonstrates a similar score to Sonnet 4.5 (63%). Minimax-M2 surpasses Gemini 2.5 Pro, which has an average intelligence score of 60%, but trails behind GPT-5 (68%) and Grok4 (65%).
“MiniMax-M2 redefines efficiency for agents. It's a compact, fast, and cost-effective MoE model built for elite performance in coding and agentic tasks, all while maintaining powerful general intelligence,” the company boasts on Hugging Face.
The model’s strengths are its agentic use cases, tool use, and coding benchmarks. However, according to Artificial Analysis, it underperforms other open-weight leaders at some generalist tasks.
“MiniMax-M2 provides the sophisticated, end-to-end tool use performance expected from today's leading models, but in a streamlined form factor that makes deployment and scaling easier than ever.”
Where the new model truly shines is in the cost to run.
Built on the cost-effective Mixture-of-Experts model, the MiniMax-M2 model has 230 billion total parameters, but only 10 billion are activated to generate a token. The size of the full version of the model (16-bit weights) is 230GB, and quantized versions are yet to be released.
That’s around three times fewer than the best models from DeepSeek, a startup that shook the AI market with its free and capable offerings.
For comparison, DeepSeek models use 671 billion total parameters, activating 37 billion for each token, and require nearly 700GB of memory to load in full precision.
“MiniMax’s API is offering the model at a very competitive per token price of $0.3/$1.2 per 1M input/output tokens. However, the model is very verbose,” Artificial Analysis said in a post on X.
“MiniMax’s release continues the leadership of Chinese AI labs in open source that DeepSeek kicked off in late 2024, and which has been continued by continued DeepSeek releases, Alibaba, Z AI, and Moonshot AI.”
MiniMax explains that maintaining activations around 10 billion parameters streamlines the agentic workflow loop “plan → act → verify”, improves responsiveness, and reduces compute overhead.
MiniMax is an AI company from Shanghai, China. It was established in December 2021 by a team of several computer vision veterans and is backed by Alibaba Group and other investors.
Unlock more exclusive Cybernews content on YouTube.