OpenAI study proves LLMs still behind human engineers in over 1400 real-world tasks
OpenAI is testing AI models by evaluating benchmarks using over 1,400 actual freelance engineering tasks found on Upwork. The results prove that LLMs aren't quite ready for the real world yet.

Cheng Xin/Getty Images
OpenAI is testing AI models by evaluating benchmarks using over 1,400 actual freelance engineering tasks found on Upwork. The results prove that LLMs aren't quite ready for the real world yet.
A new OpenAI study released on Tuesday measured the performance capabilities of three of today's most popular large language models (LLMs) and found that human software engineers are still at the top of the engineering food chain.
The latest benchmark project, SWE-Lancer, pitted the models against 1,488 freelance software engineering tasks found on Upwork – tasks OpenAI says would be worth over $1 million in real-world payouts.
The models used in the evaluations were OpenAI’s GPT-4o and o1 models and Anthropic’s Claude 3.5 Sonnet, with Claude hitting the most benchmarks of the trio.
OpenAI’s goal of mapping model performance to monetary value is to “enable greater research into the economic impact of AI model development,” it said.




Today we’re launching SWE-Lancer—a new, more realistic benchmark to evaluate the coding performance of AI models. SWE-Lancer includes over 1,400 freelance software engineering tasks from Upwork, valued at $1 million USD total in real-world payouts. https://t.co/c3pFcL41uK
undefined OpenAI (@OpenAI) February 18, 2025
The AI company explained that the SWE-Lancer tasks consisted of independent engineering and managerial tasks ranging from $50 bug fixes to $32,000 feature implementations. OpenAI said the models themselves decided between technical implementation proposals.
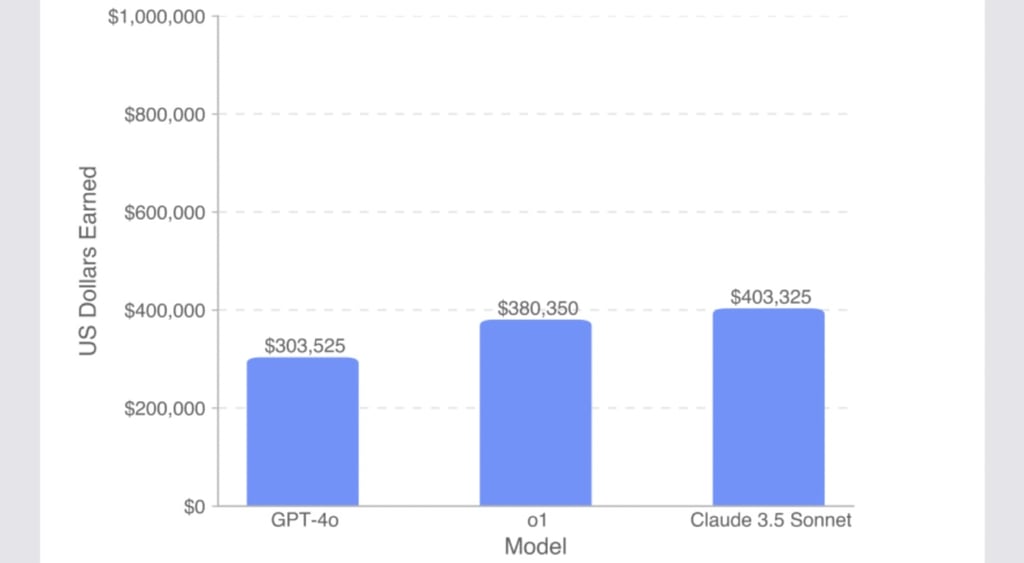
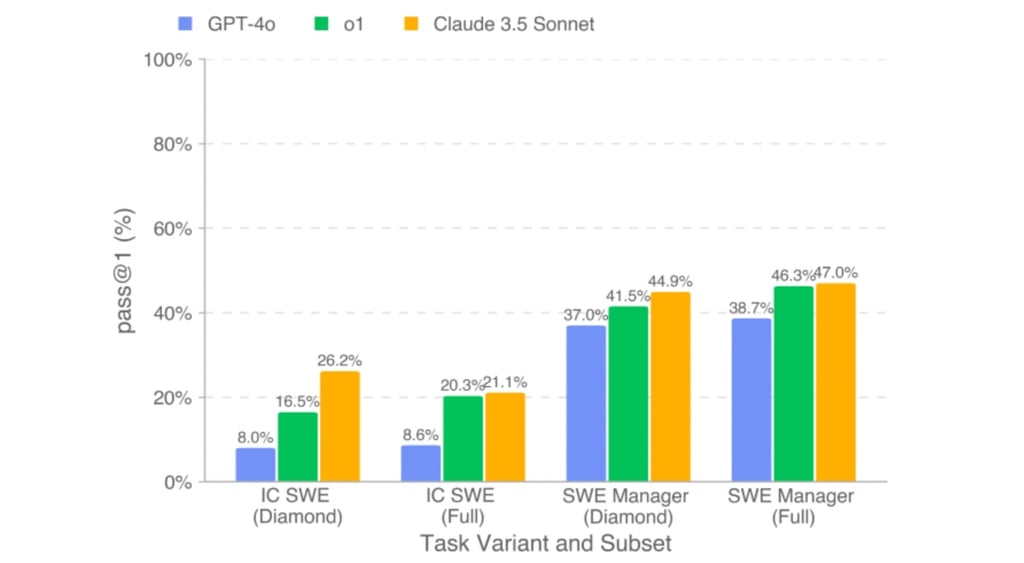
Claude 3.5 Sonnet scored the highest completion rate at 26.2% on IC SWE tasks (earning $208,000 out of $500,800) and 44.9% on SWE Management tasks (earning $400,000 out of $1,000,000).
In the end, after evaluating the models’ performance, OpenAI ‘s research paper concluded that “frontier models are still unable to solve the majority of tasks” – at least for now.
“When OpenAI announced SWE-Bench Verified in August 2024, GPT-4o scored 33%; today, their o3 reasoning model achieves SOTA [State of the Art benchmark] at 72%, highlighting the need for unsaturated evaluations that reflect the complexity of real-world software engineering,” the Microsoft-backed AI start-up said.
How it worked
Independent tasks, such as “on both mobile and web, interaction with APIs, browsers, and external apps, and validation and reproduction of complex issues,” were graded with end-to-end tests and triple-verified by experienced software engineers.
Managerial decisions, in which the SWE would act as the technical lead on projects such as solving application logic and UI/UX development, were assessed against the choices of the originally hired engineering managers for that task.
And, although it was said that roughly 90% of the tasks were bug fixes, “Diamond” level tasks, considered the most advanced, were shown to have taken engineers on GitHub an average of 26 days to solve, with nearly 50 comments on those specific threads.
To note, the agents were set up to run in a Docker container with the repository preconfigured. Remote access to GitHub and the Internet was closed to prevent the models from retrieving external information.
What makes the study different from other benchmark evaluations is that the tasks involve "user-facing products with millions of real customers," as opposed to previous testing that “has largely focused on issues in narrow, developer-facing repositories,” OpenAI said.
Other benchmark tasks evaluated in the study included new features and enhancements, server-side logic, system-wide quality related to refactoring code, performance optimization, and reliability improvements.
According to the research, about 35% of the total tasks were worth more than $1000, and about 34% were paid out between $500 and $1000. All the payouts were based on “the actual amount paid to the freelancer who completed it,” OpenAI said.
OpenAI said that eventually, AI models with advanced engineering capabilities comparable to their human counterparts are expected to “enhance productivity, expand access to high-quality engineering capabilities, and reduce barriers to technological progress.”
However, OpenAI also warns these capable AI models could negatively impact the labor market when it comes to short-term demand for entry-level and freelance software engineers, as well as “have broader long-term implications for the software industry.”