Cloudflare CEO issues an apology as the worst service disruption since 2019 affects everyone, from major banks to mom-and-pop businesses
As Cloudflare fully recovers from an hours-long outage on Tuesday impacting millions, the company assures customers in its post-mortem that the incident was not the result of a cyberattack or malicious activity.

Smith Collection/Gado/Getty Images
As Cloudflare fully recovers from an hours-long outage on Tuesday impacting millions, the company assures customers in its post-mortem that the incident was not the result of a cyberattack or malicious activity.
- Cloudflare confirms full recovery from Tuesday's outage that downed ChatGPT, X, Spotify, and dozens of other sites.
- Cloudflare CEO Matthew Prince confirms "bad configuration file" in Bot Management system, not a cyberattack, caused Cloudflare's worst service interruption since 2019.
- Prince issues detailed technical post-mortem with personal apology, promising system hardening to prevent future failures.
Key Takeaways by nexos.ai, reviewed by Cybernews staff.
Cloudflare says its services are fully restored after a technical issue caused “significant failures to deliver core network traffic” for most of Tuesday.
The Cloudflare outage, which the company began tracking at about 6:30 a.m. Eastern Time (11:20 GMT), impacted thousands, if not millions, of internet users worldwide, cutting off access to the web and to sites like ChatGPT, X, Discord, Spotify, and DoorDash.
Even the internet monitoring site Downdetector was experiencing intermittent disruptions, as witnessed by the Cybernews team.





Cloudflare co-founder & CEO Mathew Prince released a blog post about 12 hours later, detailing exactly how the outage unfolded, and profusely apologizing for “Cloudflare's worst outage since 2019.”
“We let the Internet down today. Here’s our technical post-mortem on what happened. On behalf of the entire @Cloudflare team, I’m sorry,” Prince said in a post on X.
“An outage like today is unacceptable, Prince reiterated in the blog post. “On behalf of the entire team at Cloudflare, I would like to apologize for the pain we caused the Internet today,“ the CEO said.
“We've architected our systems to be highly resilient to failure to ensure traffic will always continue to flow,” Prince explained, adding that since the 2019 incident, "we've not had another outage that has caused the majority of core traffic to stop flowing through our network.”
What caused the Cloudflare outage?
The Cloudflare outage was said to be triggered by a “bad configuration file” used by its Bot Management system (more on that below), affecting several of Cloudflare’s cloud networking services.
“The issue was not caused, directly or indirectly, by a cyber attack or malicious activity of any kind,” Prince wrote in the blog.

Instead, the issue began with a change to the permissions for one of Cloudflare’s database systems, the blog stated.
Those changes led to the database "outputting multiple entries into a ‘feature file'" used by the bot system, causing the file to double in size.
The “larger-than-expected feature file was then propagated to all the machines that make up Cloudflare’s network,” with the size of the configuration file triggering an error and ultimately causing the software to fail.
“The software running on these machines to route traffic across our network reads this feature file to keep our Bot Management system up to date with ever-changing threats,” it said.
Cloudflare's Bot Management system helps protect users against threats such as credential stuffing, web scraping, and DDoS attacks by detecting and blocking malicious bot traffic in real-time using machine learning and heuristics, according to its website.
Initially, the team believed the disruption was due to a distributed denial-of-service (DDoS) attack due to the blocked traffic flow, but eventually realized the system failure was caused by the multiplying configuration file.
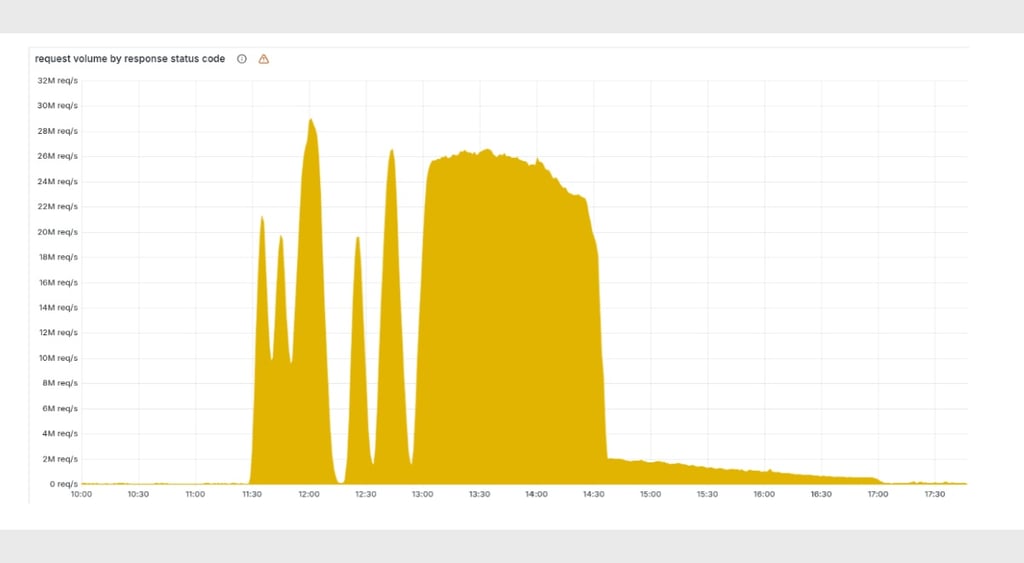
By 14:30 GMT, Cloudflare had announced that “a fix has been implemented,” but that the system was still experiencing latency issues and "mitigating several other issues remaining post-deployment," with complete restoration happening a few hours later.
Why does it matter?
The world’s leading “connectivity cloud” powers internet requests for millions of websites across the globe, serving 81 million HTTP requests per second across its network.
The majority of customers were reporting server connection and website issues, as well as problems logging in and using the Cloudflare Dashboard.
Besides OpenAI’s ChatGPT and ChatGPT Zero, plus those mentioned earlier, other websites reported to be down Tuesday included Coinbase, Shopify, Uber, Uber Eats, NJ Transit, UPS, Dropbox, Zoom, Canva, Grindr, and League of Legends.
OpenAI’s Sora and Anthropic’s Claude AI chatbots were also affected.
“Customers, from major banks to small mom-and-pop businesses, are struggling to do business and fulfill customer requests. From reputation to the bottom line, Cloudflare is one of those systems that businesses don't realize they need or even use sometimes. But when it's down, they feel it," said Jason Long, founder of SupportMy.Website.

Cloudflare powers roughly 19% of all active websites, as well as the websites for 35% of all Fortune 500 companies, according to Long’s company.
The global disruption happens to come on the heels of the October 20th Amazon Web Services (AWS) outage, which affected tens of thousands of companies and internet users for nearly 24 hours.
Curious what others think about this story? Contribute your thoughts to the debate below.
Caused by a Domain Name Server (DNS) resolution failure – the AWS outage impacted over 1,000 companies, including Snapchat, Reddit, Roblox, and Venmo, as well as Coinbase, Amazon Alexa, MyFitnessPal, and Microsoft Office and Teams, which depend on the cloud service provider to run their applications, software, and store data.
Additionally, the Microsoft Azure cloud computing platform and Microsoft 365 Copilot productivity software suite went down for thousands of users in October, also blamed on a configuration error.
Cloudflare outage. The aftermath
Now that systems are “back online and functioning normally,” Prince says the team is already working on hardening its systems to avoid similar failures in the future.
“We've architected our systems to be highly resilient to failure to ensure traffic will always continue to flow. When we've had outages in the past it's always led to us building new, more resilient systems," Prince said.
Follow-up steps are said to include the following:
- Hardening ingestion of Cloudflare-generated configuration files
- Enabling more global kill switches for features
- Eliminating the ability for core dumps or other error reports to overwhelm system resources
- Reviewing failure modes for error conditions across all core proxy modules
Still, it wasn’t all doom and gloom for the Cloudflare team. About an hour after releasing the post-mortem on the Cloudflare website and X, Prince humorously reposted a message from Utah’s Park City Transit (PCMC) on his profile.
Apparently, the transit app for the city’s public transportation system went down just before the evening rush hour on Tuesday. (Park City famously hosts the annual Sundance Film Festival.)
“Our @transitapp is currently experiencing technical disruptions, impacting real-time bus information. We apologize for the inconvenience & are working on getting this back online,” the PCMC said.
To which Prince replied: “Not my Fault.”
FAQ about the Cloudlare outage
What is Cloudflare?
Cloudflare is an internet infrastructure and security company that speeds up, protects, and routes web traffic using a global edge network.
Was Cloudflare breached?
The company said that the incident was not the result of a cyberattack or malicious activity.
What caused the Cloudflare outage?
Cloudflare CEO Matthew Prince confirmed "bad configuration file" in Bot Management system, not a cyberattack, caused Cloudflare's worst service interruption since 2019.
FAQ by nexos.ai, reviewed by Cybernews staff.