Meta uses your data to train its AI. Can you opt-out?
Meta has vast troves of personal user data. However, the company is now allowing users to opt-out of their data being used to train AI by third parties.

Image by Koshiro K | Shutterstock
Meta has vast troves of personal user data. However, the company is now allowing users to opt-out of their data being used to train AI by third parties.
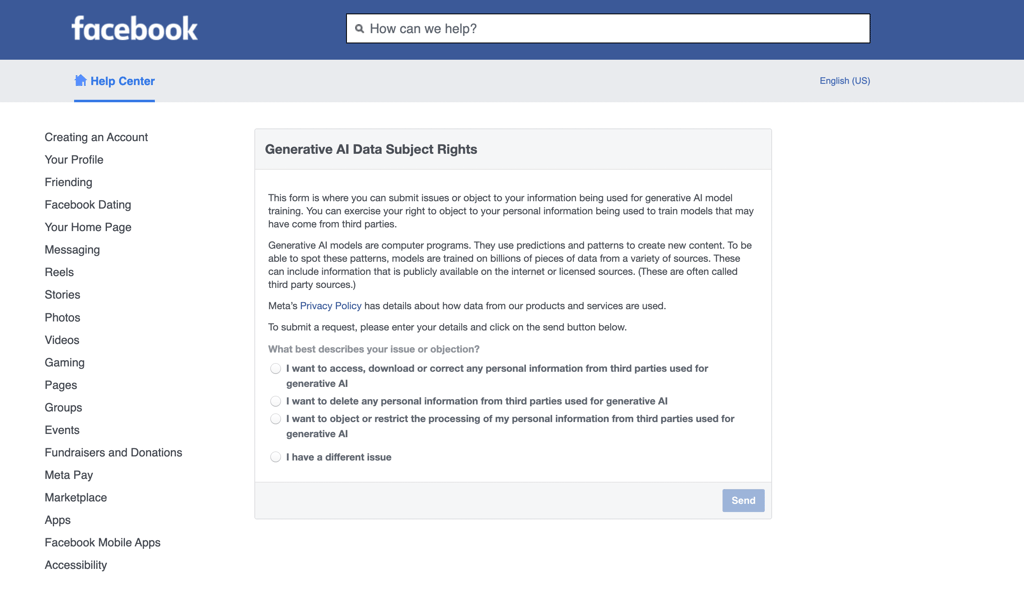
On Facebook, users can fill in a form called “Generative AI Data Subject Rights,” which enables them to access, download, correct, or delete any personal information used for generative AI.
There’s also the option to restrict the processing of personal data to train AI models. In the form, users need to fill in their name, surname, place of residency, and email address.
The company says that users can object to their personal information being used to train models “that may have come from third parties.” However, users aren’t given the choice to accept or reject their data being used to train Meta's AI.




Meta’s generative AI policy states that they train their models on publicly available data from the internet, licensed data, and information from Meta’s products and services. The company states that when it collects public information from the internet or licensed data from other providers to train its models, it “may include personal information.”
Meta has been developing a range of AI tools and intends to integrate generative AI text, image, and video generators across its social media platforms. Additionally, the company is working on internal AI tools.
This year, Meta has made a push with its AI development by releasing the LLaMA AI model. Another major update was the release of SeamlessM4T, an AI model that will enable speech and text translations for up to 100 languages.
For users on the European continent, the company will provide users an option to opt out of AI-driven personalization in their social media feeds and get posts in chronological order instead.
The move comes to comply with the European Union’s Digital Services Act (DSA) aimed at reducing the spread of illegal content and disinformation as well as encouraging transparent advertising.