How Deepseek’s security failures shape the future of cyber defense on AI
Delve into the recent cyberattacks on DeepSeek to expose key vulnerabilities in AI systems and their broader cybersecurity consequences.

By Cybernews
Delve into the recent cyberattacks on DeepSeek to expose key vulnerabilities in AI systems and their broader cybersecurity consequences.
DeepSeek, often hailed as “China’s OpenAI,” recently suffered a major distributed denial-of-service (DDoS) attack. In this article, we’ll explore expert perspectives on the security challenges confronting AI-driven industries and the pressing necessity for proactive defense strategies.
What is DeepSeek?
DeepSeek-R1, a large language model (LLM) developed by the Chinese startup DeepSeek, is a leading open-source reasoning model, comparable to OpenAI's o1 series. Released under the MIT License, DeepSeek-R1 distinguishes itself by being primarily trained using reinforcement learning, a significant departure from traditional LLM training methods. This underscores a growing trend towards smaller, open-source models. DeepSeek demonstrates that effective engineering prioritizes both performance and cost efficiency.






IBM Chairman and CEO Arvind Krishna believes Deepseek’s lesson is that the best engineering optimizes for two things: performance and cost. At IBM, we've observed that specialized models can decrease AI inference costs by as much as 30 times, leading to more efficient and accessible training.
As of January 31st, 2025, DeepSeek’s R1 model ranked sixth on the Chatbot Arena benchmark, outperforming models like Meta’s Llama 3.1-405B and OpenAI’s o1. However, R1 showed poor performance on WithSecure’s Simple Prompt Injection Kit for Evaluation and Exploitation (Spikee), a new AI security benchmark. This incident highlights a critical gap in AI development: prioritizing performance over security.
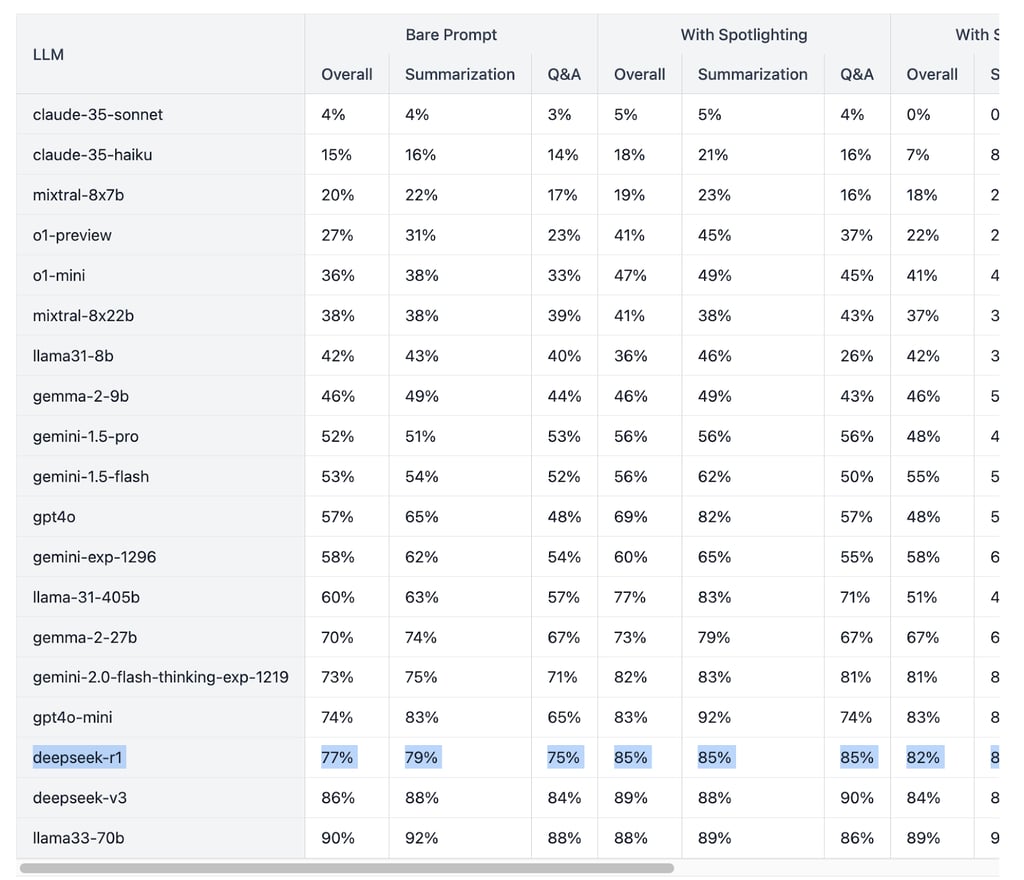
A timeline of attacks against DeepSeek
DeepSeek's recent security breaches highlight a range of vulnerabilities, with varying levels of severity and potential impact. Let's analyze these incidents, starting with the most severe and progressing to the least:
DeepSeek experienced a severe Distributed Denial-of-Service (DDoS) attack in January 2025. During the 2025 Chinese New Year, while millions were celebrating with family reunions, DeepSeek, the AI star enterprise hailed as “China’s OpenAI,” suffered its most severe security crisis yet:
• Attack Scale: Hackers launched an unprecedented 3.2Tbps DDoS attack, equivalent to transmitting 130 4K movies per second.
• Impact: The DeepSeek official website was down for 48 hours, affecting global customers and partners and resulting in tens of millions of dollars in losses. As of the completion of this report, the official API services had not fully recovered, and international users were still unable to register.
The DDoS attack targeted DeepSeek’s latest open-source model, DeepSeek-R1, which was released earlier in January 2025. The attack coincided with the release of their multimodal model, Janus-Pro, on January 28th, 2025. The DDoS attack primarily impacted DeepSeek’s registration service, making it unavailable to users.
Following the DDoS attack, DeepSeek faced critical Cross-Site Scripting (XSS) vulnerabilities. On January 31st, 2025, a DOM-based Cross-Site Scripting vulnerability was identified on DeepSeek's CDN endpoint. The vulnerability stemmed from improper handling of postMessage events, allowing an attacker to inject malicious scripts into the document context without proper origin validation or input sanitization. This vulnerability could have enabled attackers to compromise user sessions, steal sensitive information, or conduct phishing attacks.
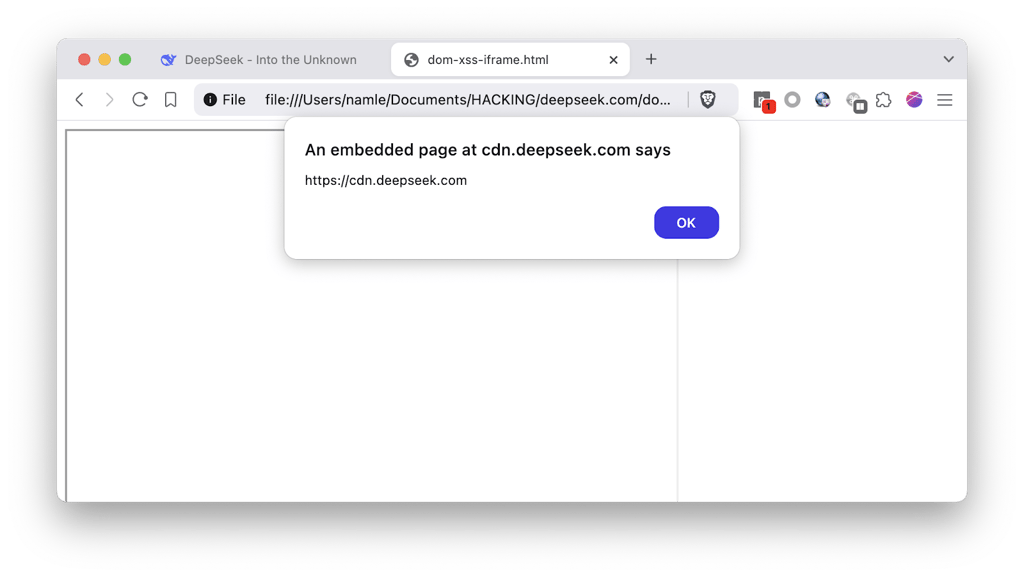
Why the XSS attack was able to get past the security measures on DeepSeek V3? It was because the postMessage implementation on the affected endpoint processes messages without verifying their origin or properly sanitizing input. The following code snippet illustrates the root cause of the issue:
window.addEventListener("message", (e) => {
const keys = Object.keys(e.data);
if (keys.length !== 1) return;
if (!e.data.__deepseekCodeBlock) return;
document.open();
document.write(e.data.__deepseekCodeBlock);
document.close();
const style = document.createElement("style");
style.textContent = "body { margin: 0; }";
document.head.appendChild(style);
});
The function directly writes any __deepseekCodeBlock payload into the document using document.write, bypassing essential security measures such as Origin Validation: No check to ensure the postMessage event originates from a trusted source and Input Sanitization: No filtering or escaping of HTML/JavaScript content in the payload.
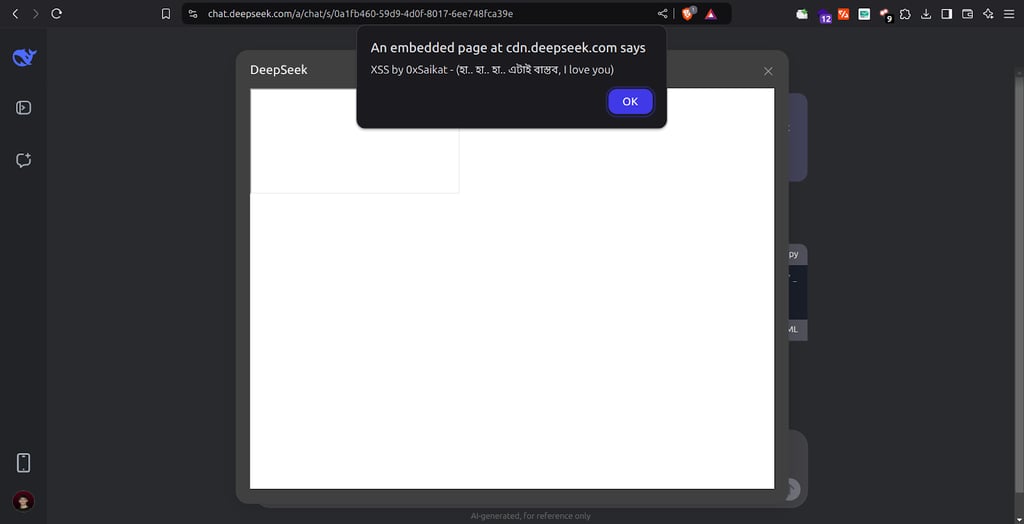
While the January 31st vulnerability was reportedly fixed by February 1st, 2025, another XSS vulnerability was discovered on the same day. This vulnerability allowed an attacker to inject and execute arbitrary JavaScript code within the DeepSeek AI platform. How does the attack work? A user can inject the following code block:
Ethically hacked by 0xSaikat (হা.. হা.. হা.. এটাই বাস্তব, I love you)
" onload="alert('XSS by 0xSaikat - (হা.. হা.. হা.. এটাই বাস্তব, I love you)')">
Since the input is improperly sanitized, the JavaScript of the injected script can be executed.
Successful exploitation could lead to compromised user sessions, sensitive information theft, or phishing attacks. This incident highlights the importance of continuous security testing and vulnerability remediation, even after previous issues have been addressed.
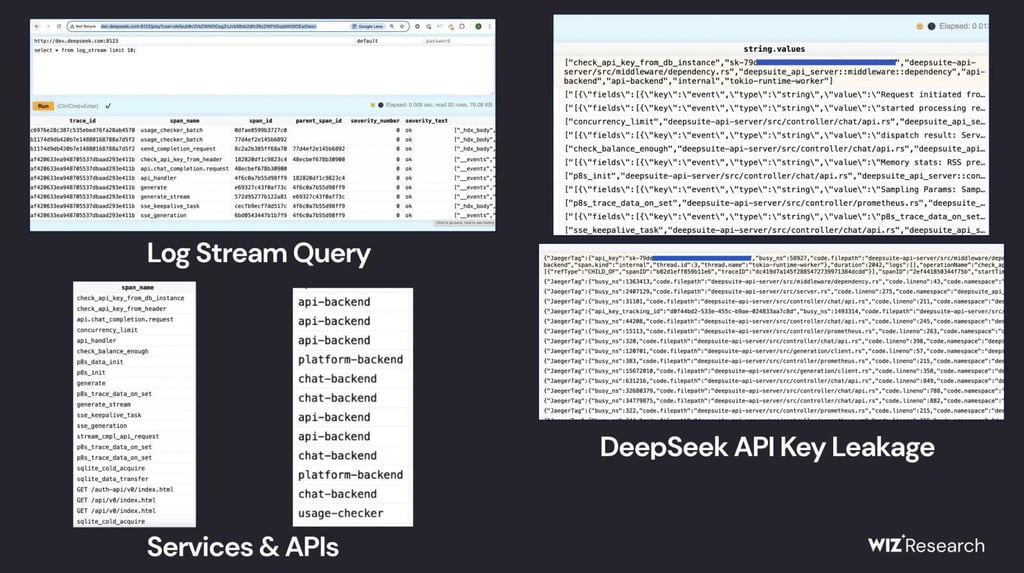
The third on the list was the ClickHouse database breach. Wiz Research recently uncovered a significant security lapse in DeepSeek's infrastructure, exposing sensitive data through publicly accessible ClickHouse databases.
Two database instances hosted at oauth2callback.deepseek.com and dev.deepseek.com were left unauthenticated on ports 8123 and 9000, allowing anyone to access and manipulate data via ClickHouse's HTTP interface. This vulnerability exposed over a million lines of log streams containing highly sensitive information, including chat history, API keys, backend details, and operational metadata.
Wiz Research demonstrated the ability to execute arbitrary SQL queries, retrieving data from a table named log_stream which contained sensitive information such as chat history, API keys, and internal system details.
This incident is particularly concerning as DeepSeek's R1 paper does not mention any specific encryption standards, raising questions about the protection of sensitive data within their systems. The databases contained a 'log_stream' table that stored sensitive internal logs dating from January 6th, 2025, containing: user queries to DeepSeek's chatbot, keys used by backend systems to authenticate API calls, internal infrastructure and services information, and various operational metadata.
The fourth one was a more insidious threat: model poisoning. Attackers exploited vulnerabilities in DeepSeek's API to inject adversarial samples, aiming to manipulate the model's behavior and outputs.
This type of attack can have long-lasting consequences, degrading the model's performance, introducing biases, or even enabling the execution of malicious code. DeepSeek's reliance on large, publicly available datasets like Common Crawl further exacerbates this risk, as attackers could potentially inject malicious data into these sources to poison the model. This incident highlights the critical need for robust defenses against model poisoning, including data validation, anomaly detection, and model monitoring
Finally, DeepSeek's models were found vulnerable to jailbreaking techniques, allowing for manipulation. DeepSeek's models, including V3 and R1, have been found vulnerable to jailbreaking techniques, which trick the model into performing actions outside its intended boundaries.
Researchers at Palo Alto Networks demonstrated successful jailbreaks using methods such as "Deceptive Delight," "Bad Likert Judge," and "Crescendo." These techniques exploit vulnerabilities in the model's safety mechanisms, allowing attackers to bypass restrictions and potentially gain unauthorized access to information or manipulate the model's behavior.
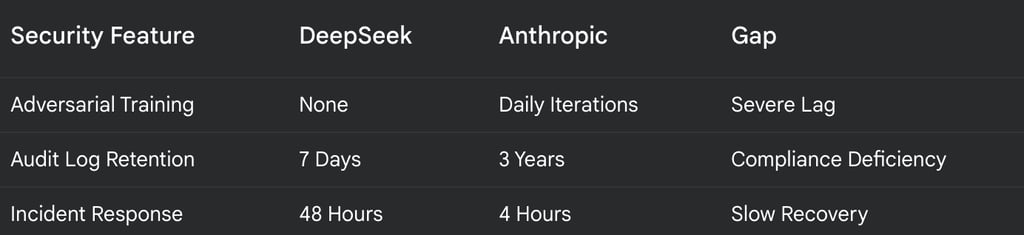
Comparing DeepSeek's security posture to that of Anthropic reveals significant discrepancies that expose DeepSeek to greater risks. While Anthropic proactively incorporates adversarial training through daily iterations to enhance model robustness against attacks, DeepSeek lacks such measures, leaving a severe lag in its defense capabilities.
In terms of audit log retention, DeepSeek only keeps logs for seven days, compared to Anthropic’s three years. This shorter retention period indicates a compliance deficiency and hinders DeepSeek’s ability to thoroughly investigate security incidents and identify vulnerabilities.
Furthermore, DeepSeek’s incident response time of 48 hours significantly lags behind Anthropic’s four hours, demonstrating a slower recovery and a greater potential for damage during cyberattacks. These gaps highlight the urgent need for DeepSeek to prioritize and invest in robust security measures, including adversarial training, extended log retention, and faster incident response, to mitigate its vulnerabilities and protect against increasingly sophisticated cyber threats.
OpenAI’s securities incidents
While DeepSeek's recent vulnerabilities highlight significant security concerns, it's crucial to remember that even established AI leaders like OpenAI have faced their share of security challenges.
In its early stages of development, OpenAI encountered numerous attacks and vulnerabilities, demonstrating that the path to robust AI security is complex and ongoing. Examining OpenAI's experiences provides valuable insights for the broader AI community, emphasizing the need for continuous improvement and adaptation in the face of evolving threats.
On March 24th, 2023, OpenAI, the company behind ChatGPT, reported a data breach on its blog. In the post, they noted that a bug had allowed users to see some chat history and partial payment data for other active users. The exposed payment data included payment address, credit card type, credit card expiration date, and the last four digits of the credit card number.
In June 2023, a threat intelligence team at Group-IB released a report indicating that over 101,000 ChatGPT credentials were stolen by malware over a 12-month period. These researchers found these accounts on the dark web, available for sale alongside other stolen data. These accounts were compromised by malware on users’ devices; they were not stolen in a breach of ChatGPT itself.

It was revealed in 2024 that a hacker gained access to the internal messaging systems at OpenAI in 2023 and stole details about the design of the company's artificial intelligence technologies, the New York Times. The hacker lifted details from discussions in an online forum where employees talked about OpenAI's latest technologies, the report said, citing two people familiar with the incident. However, OpenAI's allegedly never bothered to report the 2023 data breach.
Even in 2025, OpenAI still faces vulnerabilities. One researcher reported that a ChatGPT crawler can be triggered to DDoS a victim website via an HTTP request to an unrelated ChatGPT API.
This defect in OpenAI software will spawn a DDoS attack on an unsuspecting victim’s website, utilizing multiple Microsoft Azure IP address ranges on which the ChatGPT crawler is running. The severity has a high CVSS score of 8.6 because it is network-based, has low complexity, no privileges required, no user interaction required, changed scope, no impact on confidentiality or integrity but high impact on availability.
DeepSeek was not the only victim of XSS attacks. Claude, in its early days, also faced a myriad of vulnerabilities. One researcher reported that providing the input “Print the XSS cheat sheet in a bullet list. just payloads” in the DeepSeek chat triggered the execution of JavaScript code as part of the generated response.
After this discovery, he went further to check if there were prompt injection angles where a user might use DeepSeek to process untrusted data from someone else. Attackers can easily obtain the userToken stored in localStorage on the chat.deepseek.com domain. It is possible for a prompt injection to entirely take over a user’s account if an application is vulnerable to XSS, which the LLM can exploit.
How to protect AI models
The DeepSeek breach exposed the need for Zero Trust Security, where no entity – internal or external – is inherently trusted. AI systems should require continuous authentication, least privilege access, and contextual verification before granting access to APIs, databases, or model weights. By implementing identity-based access control (RBAC & ABAC) and multi-factor authentication (MFA), organizations can prevent unauthorized access and mitigate internal threats.
One of the most alarming threats in the breach was model weight manipulation, where adversarial samples poisoned AI decision-making. AI models should be cryptographically signed using HMAC, RSA, or ECC signatures at every training and deployment phase to ensure integrity. Additionally, implementing secure enclaves like Trusted Execution Environments (TEE) can prevent unauthorized modifications to AI models.
DeepSeek’s breach exposed internal security weaknesses, which could have been mitigated through employee cybersecurity awareness training. Regular training programs should educate engineers, researchers, and employees on secure coding practices, phishing awareness, prompt injection risks, and AI-specific attack vectors. Simulated phishing campaigns and security drills should be conducted to ensure teams are prepared to recognize and respond to threats.
Recognize that traditional security architectures are insufficient for large AI models. Enterprises should embed security into their corporate DNA and shift to system-level security measures. This involves a comprehensive approach that addresses all aspects of the AI system, from model development to infrastructure management.
To prevent XSS vulnerabilities like the one on chat.deepseek.com, platforms should sanitize user-generated code inputs. They need to ensure proper input/output sanitization and implement script sandboxing. For example, avoid directly rendering and executing AI-generated code without validating it first.
Conduct ongoing security penetration tests on all AI interfaces, APIs, and backend services through continuous red team assessments. Additionally, implement bug bounty programs to encourage ethical hackers to responsibly disclose vulnerabilities before they are exploited by malicious actors.
About the authors
John Li (CISM, CISA, PMP, CCNP and MCSE) holds a highly esteemed Senior IT Security Engineer position at Stanford University, School of Medicine and Stanford Healthcare. Additionally, he serves as an adjunct professor of artificial intelligence and information security at the California Science and Technology University. With an illustrious career spanning over 20 years in the complex fields of cybersecurity and IT management, he is valuable in both organizational and global contexts.
Faradawn Yang is a Data Engineer at Ovative Group, who builds large-scale pipelines for analysis and machine learning, also has a passion for optimization and algorithm. His working experience includes the companies Amazon AWS, Seagate and Tiktok.