‘Inner monologue’ makes AI smarter
Scientists trained an AI system to think before speaking, which improved the algorithm's common sense tremendously.

Image from Shutterstock
Scientists trained an AI system to think before speaking, which improved the algorithm's common sense tremendously.
It’s common for humans to pause to think when writing or talking. Reasoning helps to understand more complicated concepts because much of the meaning of a text is hidden between the lines. Without reasoning, knowledge stays shallow.
AI models have so far failed to reach human-level common sense and contextualization abilities. Reasoning about the implications of how text influences later text can enhance AI’s model performance across tasks.
Scientists from Stanford University and Notbad AI, an AI marketing solutions firm, have used a technique called QuietSTaR, which helps AI models think before responding to a prompt.
This technique involves instructing the model to generate multiple internal rationales simultaneously before the model produces the final response. These rationales contribute to either answering the question accurately or not. By discarding rationales that proved incorrect, the model learns and improves future performance.






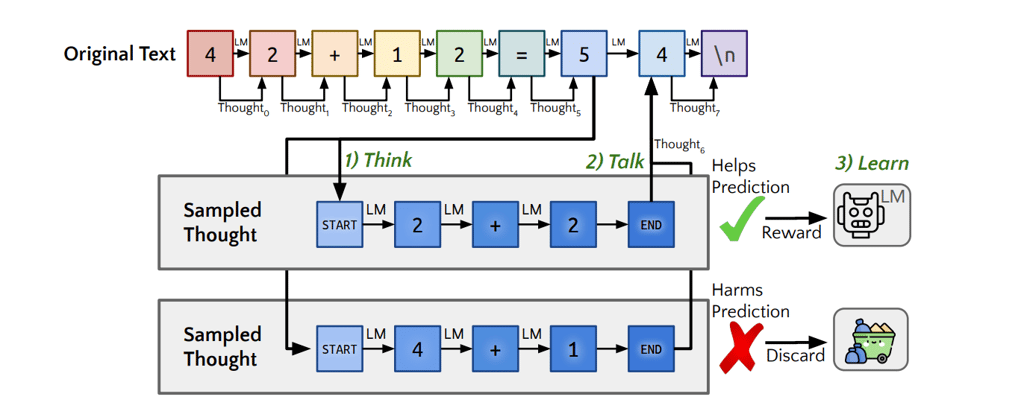
The scientists trained the model explicitly on unstructured text data, which trained the language model to reason generally from text rather than on curated reasoning tasks or collections of reasoning tasks.
After training, the AI achieved a 47.2% score on a reasoning test, compared to 36.3% before training. However, it still struggled with a school math test (GSM8K), achieving a score of 10.9%. Despite the low result, it was almost double its initial score of 5.9% before training.
“On multiple tasks, we demonstrate that thinking allows the LM to predict difficult tokens better than one trained on the same web text, improving with longer thoughts,” write researchers in a paper published on March 14th.