How your personal information is training AI

AI has come a long way in just a few short years. Something that once produced incoherent text and distorted images is now used as a personal assistant or to create realistic photos and videos. Just a few years ago, AI struggled to generate human hands without extra fingers. Today, we scroll past AI-generated videos and flawless product shots without even realizing they’re fake.
Large language models (LLM) have improved a lot and continue to do so. Yet, not many realize that our information fuels AI progress. It trains on the content we post online, the questions we ask, and the photos we upload. Whether it’s someone asking for health advice or uploading a selfie for a trend, that data doesn’t just vanish. It becomes part of what trains and shapes the next AI model.
- Despite the growing concerns, many users upload tons of biometric and personal data to LLMs in the form of photos, videos, and sensitive information, which is then used to train AI.
- Public social media content can be scraped and used to train AI, meaning your posts might be fueling these systems.
- Some AI models can be trained on copyrighted material, leading to legal disputes over who owns the rights to this content.
- Personal data can be collected and used without your knowledge, raising serious privacy concerns.
- Many users are unaware of how much data they’re giving away and how AI is using it.
Inside the AI training process
The process of training AI like an LLM is very similar across industries. This approach allows the AI to learn by itself, improve with minimal human input, and get better over time.






Stage 1: data collection
The first stage begins with AI models collecting vast amounts of publicly available information. Tons of learning data is extracted from the internet using crawlers. At this stage, AI learns to identify patterns, create systems, and organize the information.
Stage 2: finding purpose and fine-tuning
Next, the model is trained based on its future purpose. At this stage, a model can be trained to produce images in a certain artistic style, create videos, or respond in a particular tone. This training involves providing special datasets and adjusting parameters to tweak the behaviour.
Stage 3: human feedback and improvement
Finally, a human evaluates the model. Each AI response is rated, signaling which outputs are helpful, accurate, or of high quality. The AI uses these good examples and learns to replicate a satisfactory response. Even after the release, AI systems continue learning from user interactions as well as updates provided by developers and researchers.
Your personal data is training AI
Most LLMs are now primarily trained on publicly available information. During this process, advanced filters are used to remove inappropriate content, spam, and other low-quality data. Some models, like ChatGPT, also use information from their third-party partners and information provided by users, trainers, and researchers.
OpenAI acknowledges that it may use personal information to train its models if it’s available online.

Meta takes this even further. It uses publicly available data from Facebook and Instagram to train its AI models. While Meta insists that it only uses information that is public, its history of privacy controversies has made many skeptical. Moreover, opting out of Meta's AI training is complicated, discouraging many users from doing so.
In short, all AI models learn from public data. However, personal information and user input play a significant role. Access to personal data can make the LLM much more advanced and accurate.
The hidden cost of AI trends
From fun trends to private conversations, people give AI staggering amounts of personal information. Many don’t realize the risks of putting that much information into a machine that learns from anything you throw its way.
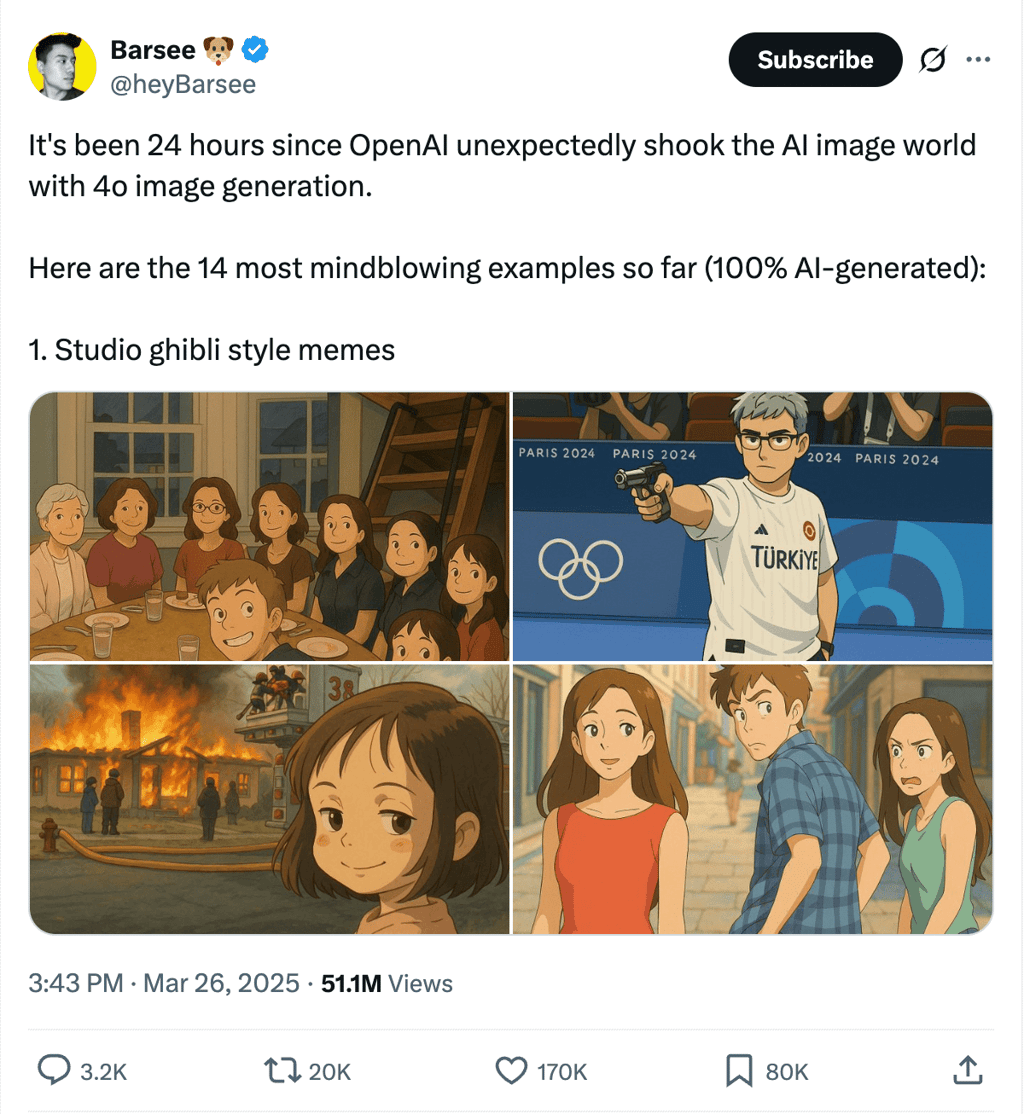
Not long ago, people uploaded their photos to ChatGPT to create Studio Ghibli-style photos. Then came the AI action figure trend, which also requires a photo. While these trends might seem harmless, they lead to a bigger issue: AI models gaining access to your biometric data.
As AI becomes an irreplaceable tool in our daily lives, many are turning to it for sensitive matters. Some use it to get health advice, inputting detailed medical histories, and highly sensitive information. Others treat it like a therapist, sharing personal struggles, trauma, and even information about friends and family. However, few understand where that data goes or how it’s used.
People also rely on AI to handle work tasks, from writing emails to analyzing data. However, by doing so, many unknowingly share confidential company information, sensitive details, or client data. Since AI systems learn from the data they receive, there’s always a risk that this sensitive material becomes part of a future response.
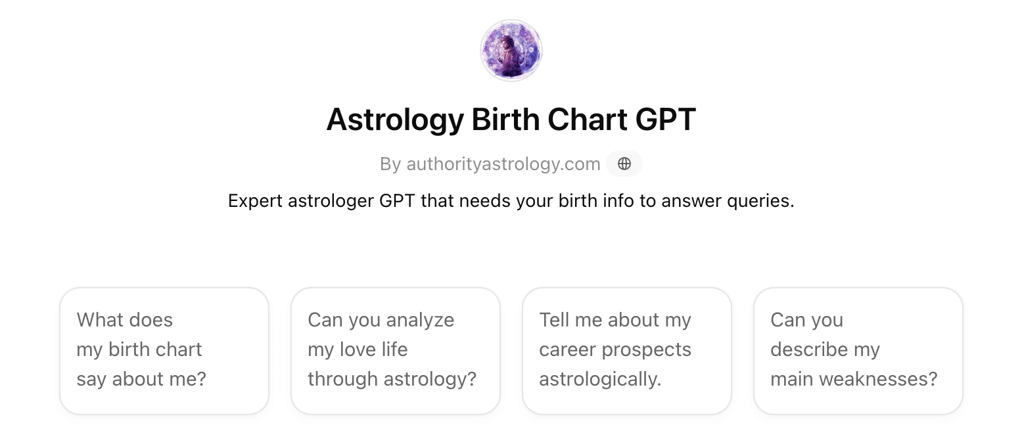
There are niche tools like astrology bots asking for birth date and location – information you wouldn’t hand out freely. That said, the list goes on. The more we interact with AI, the more data we hand over. As a result, LLMs aren’t just trained on publicly available data anymore. Many learn from our personal and sensitive information, which we share for fun trends or to save time.
Who actually owns AI-generated content?
The question of copyright law and AI is a tricky subject. When AI generates images, texts, or art, it’s unclear who owns it. The lines get even blurrier when AI is trained on existing, and potentially copyrighted, content without permission.
Let's take the Ghibli-style AI portraits as an example. It’s unclear whether or not OpenAI trained its image model on copyrighted Studio Ghibli artwork. If it did, it could be a case of copyright infringement. However, proving what data an AI model was trained on is nearly impossible. Often, suspicions only arise when a generated image looks too similar to a specific artist’s work.
In fact, some artists have already won lawsuits after discovering AI-generated art that mimicked their signature styles. Still, going up against tech giants is a long and costly fight — and even then, the legal outcomes are uncertain.
The debate isn’t just about art styles. Canadian news media are currently suing OpenAI for using their content without permission. Meanwhile, Meta has been accused of training its AI on pirated books. These cases could set major examples for how copyright applies to AI.
When data privacy meets AI: the line keeps getting thinner
Petabytes of data are used to train AI every day, and a lot of it comes uncomfortably close to crossing privacy lines. Publicly available content is just the beginning. Some LLMs are also trained on data purchased from third parties, which can include everything from social media posts to health records and more.
Another major concern is that if sensitive data gets leaked online, even by accident, it can be collected and used to train AI. Pairing that with the overwhelming amount of information users willingly give out to LLMs, it seems like AI can learn from anything, no matter if it’s sensitive and private data or public.

Of course, not every AI model operates completely ethically and legally, either. While some companies claim to use only publicly available data, others may push boundaries, collecting and using personal information without consent. As the line between lawful and unethical use continues to blur, the gap between AI and data privacy keeps shrinking.
The price of a picture: what can happen to your data
Every time you upload a photo of yourself to AI, you’re putting yourself in danger. Your face can be used to train models to create hyper-realistic deepfakes, recognize environments, or understand the objects in your background. And because your face is biometric data, it’s especially valuable.
This kind of information is extremely valuable. Any service that can get access to it for free is walking away with a goldmine of training data. This information can be sold to advertisers, handed over to law enforcement, or even stolen by malicious hackers. Even worse, such data can be used to spy, impersonate, or even lead to identity theft. A single video can be enough to replicate your voice, face, and body language.
Final thoughts
AI models are evolving rapidly, and they’re learning from us. Every interaction, from casual image uploads to personal queries, provides valuable data like biometric details and private information. While AI evolves rapidly, the laws meant to control it lag behind. Current regulations around data privacy and copyright in relation to AI are outdated, vague, or easy to bypass.
As major tech giants dominate AI development, avoiding involvement is nearly impossible. In the end, our data has become the fuel powering smarter, more capable AI – collected quietly, cheaply, and at a remarkable scale.