My mind was blown: running a 120B parameter AI model on a budget GPU at home
I’ve tried running plenty of open-source LLMs on my own computer, and anything larger than 32 billion parameters grinds to a halt. Then, some Redditor showed up, claiming you can run OpenAI’s newest 120B parameter model smoothly on a budget 8GB GPU. It sounded like pure fiction – until I tried it myself.

Image by Cybernews.
I’ve tried running plenty of open-source LLMs on my own computer, and anything larger than 32 billion parameters grinds to a halt. Then, some Redditor showed up, claiming you can run OpenAI’s newest 120B parameter model smoothly on a budget 8GB GPU. It sounded like pure fiction – until I tried it myself.
- Massive LLMs no longer demand data centers as a normal PC can handle them.
- A Reddit tip proved OpenAI’s huge model runs smoothly on modest home hardware.
- This could flip the economics: less cloud rent, more local control.
- Not a chart-topping chatbot, but capable enough for real work and learning.
It seems that AI companies are hammering yet another nail into what may soon become their coffin. You no longer need a data center to run a large language model (LLM) of over 100 billion parameters.
The secret sauce is the Mixture of Experts (MoE) technique, which splits one big LLM into several smaller chunks. This drastically reduces the need to move huge amounts of data in memory, enabling data processing on the processor (CPU) while offloading only key parts to a modest graphics accelerator (GPU).
Leading AI company OpenAI has recently unveiled an open LLM called gpt-oss-120b. OpenAI claims that a powerful datacenter GPU with at least 80GB is required to run this model efficiently.






But I stumbled on a Reddit post by Wrong-Historian, who claimed that the model can run smoothly on a PC with a budget 8GB GPU and 64GB of RAM. They were getting 25 tokens per second.
“Honestly, this 120B is the perfect architecture for running at home on consumer hardware. Somebody did some smart thinking when designing all of this!” the Redditor’s post reads.
So it happens that my computer also has 64GB of RAM and a GPU with even more RAM than required. It’s time to cancel some subscriptions.
Testing the claims
My Windows gaming rig has a Radeon RX 7900 XT. This AMD GPU isn’t ideal for running LLMs because its support lags behind industry-leading Nvidia cards. It has 20GB of VRAM, which is nowhere near enough to fit large LLMs, but still more than the Redditor claimed was needed.
I’ve previously attempted to run over 70B parameter models on it, like Llama or R1, but the experience was excruciating. It was usually around one token, or even less than one word, per second.
With renewed hope, I downloaded LM Studio, an app that lets you run a wide selection of AI models, if you have what it takes.
I didn’t even follow any guides and just went with the defaults: I downloaded gpt-oss-120B and got an alert that the gpt-oss-120B is too large for my system. I only got it to load after disabling all the guardrails. I loaded it with the default settings.
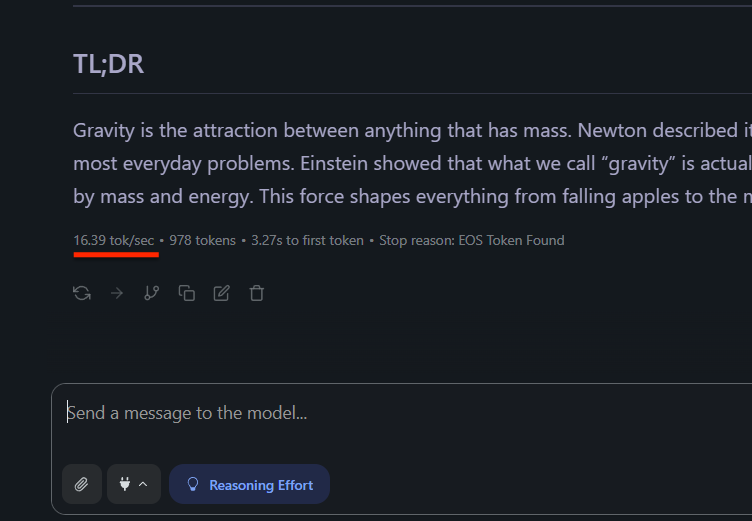
I asked the LLM to explain gravity, and Kazaam: I was getting 15-20 tokens per second immediately.
While the app used 18 out of 20 GB of my GPU’s VRAM, most of the processing was done on the CPU (Ryzen 7 7700x).
Some of the layers were offloaded to the GPU by default. I tried to tweak the model manually to move all model layers to the RAM, but they barely fit, requiring all the available RAM and even some cached memory. This hurts performance. I need more RAM.
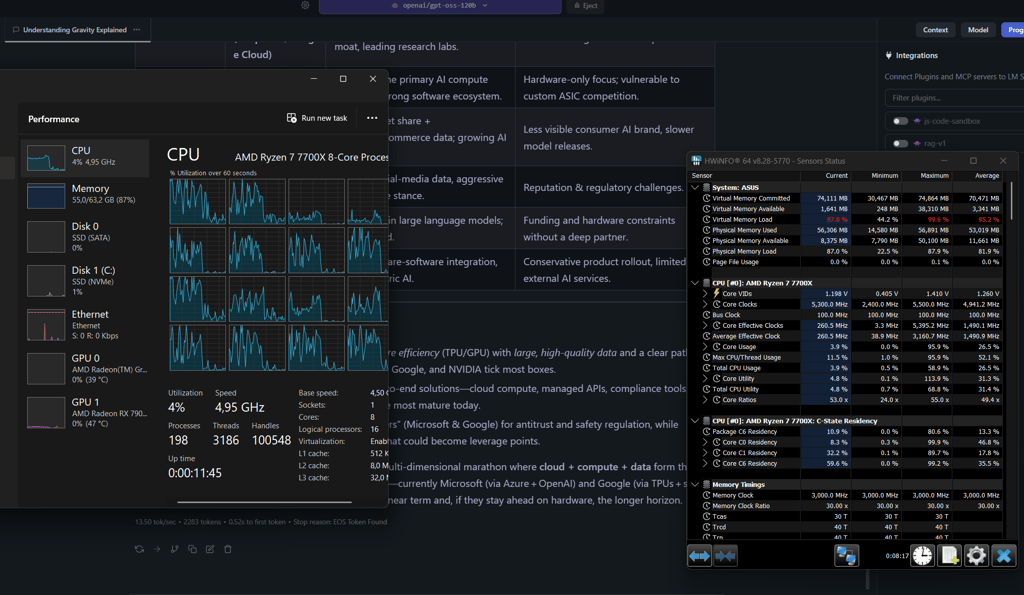
What is this witchcraft?
OpenAI’s LLM uses the Mixture of Experts (MoE) technique, and it delivers over a 20-time performance improvement compared to smaller models I had tried previously. Perhaps more importantly, it makes large LLMs actually usable on a home computer.
“You can offload just the attention layers to GPU for fast prefill,” Wrong-Historian explains on Reddit.
“No giant MLP (multilayer perceptron) weights are resident on the GPU, so memory use stays low.”
All the attention data, routing tables, KV cache for the sequence (context length), and other non-expert parameters stay on the GPU, while MoE layers stay in RAM and are processed by the CPU one chunk at a time.
“With the new MOE models, the amount of VRAM is much less of an issue. I can run GPT-OSS 120B at 30 to 35T/s on my 3090+14900K, which is the first time that a local-llm actually has been useful to me.”
The gpt-oss-120b model activates only 5.1 billion 4-bit parameters at a time. This corresponds to one layer out of 36 and four experts out of the existing 128. The CPU alone can handle this reduced load, while a larger VRAM allows more context to be kept in the GPU.
Wrong-Historian also noted that running on CPU only makes the gpt-oss-120b model very slow, because a GPU can process 16-bit floating-point layers a lot quicker.
“It's totally game-changing,” the Redditor writes.
“With the new MOE models, the amount of VRAM is much less of an issue. I can run GPT-OSS 120B at 30 to 35T/s on my 3090+14900K, which is the first time that a local-llm actually has been useful to me.”
While it’s recommended to have at least 64GB of system RAM, the overhead from LM Studio and Windows made that barely sufficient for me.
“A 96GB would be ideal. Linux uses mmap so will keep the ‘hot’ experts in memory even if the whole model doesn’t fit in memory.”
Is it any good?
During my short testing, it was obvious that gpt-oss-120 likes to provide answers in tables. Like many other models nowadays, it makes the responses too extensive. There was nothing exceptional about it, but I also couldn’t identify any major flaws.
According to the lmarena.ai leaderboard, which ranks chatbots based on human preferences and voting, the current best-ranking AI chatbots in the world are GPT-5, Gemini 2.5-Pro, Claude Opus 4.1, and other huge proprietary models.
The gpt-oss-120b only ranks 37th, which suggests people don’t feel that its responses are great overall. Even some smaller models, like Gemma-3 27B, rank higher.
This doesn’t mean that gpt-oss-120b can’t be useful. For web development tasks, gpt-oss-120b ranks 27th and is perceived as better than OpenAI’s o1 from last year. In math, it ranks 5th.
According to OpenAI, this model scores 97-98% in competition math benchmarks AIME2024 and AIME 2025, and also demonstrates impressive PhD-level science knowledge, scoring 80.1% in GPQA Diamond.
While the model might not be the chart-topper or people-pleaser, it demonstrates that it’s possible to run an over-100B parameter model with performance comparable to top models on consumer-grade tech. It’s likely we will see more large MoE LLMs emerging soon.