AI mistakes a panda for a gibbon. Why does it matter?
When people talk about faulty AI systems, they often reference a famous panda-gibbon example.

Shutterstock/Cybernews
When people talk about faulty AI systems, they often reference a famous panda-gibbon example.
Here are two almost identical pictures of a panda. One of them, AI insists, actually depicts a gibbon. Can you tell which one?







It’s the one on the right. You might have guessed at random, but there’s no way for a human to identify a picture of a gibbon, since they’re both just very similar images of the same panda. But that’s not how a machine sees it. Why is that?
This is probably one of the most famous pictures when it comes to adversarial machine learning, which refers to the deliberate confusing of machines so they can learn. Some researchers simply call it optical illusions for machines.
You might consider a certain AI system to be pretty stupid if it can’t distinguish between an obvious panda and a gibbon. But it’s not. You wouldn’t call a child stupid just because they don’t recognize the number 9. Instead, you show them a lot of different examples of how the number looks when written down, and hope that they remember and learn. That’s basically what’s happening with machine learning – experts are attempting to teach them.
But let’s get back to the famous panda-gibbon example, which gets us closer to understanding how AI works and what needs to be fixed before its widespread adoption. Especially in areas such as healthcare and finance.
In 2015, Google researchers Ian J. Goodfellow, Jonathon Shlens and Christian Szegedy published a research paper named Explaining and harnessing adversarial examples.
The problem was that if you take a data point from a certain dataset and slightly modify it, machine learning models would consistently misclassify them. They showcased the problem by forcing a neutral network to classify the panda's picture as a gibbon. What they did is add noise to the picture of a panda.
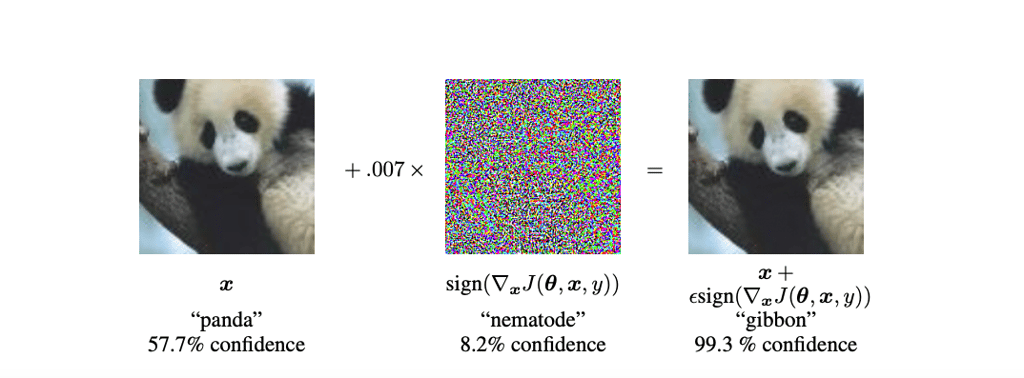
Researchers fooled the GoogLeNet neural network that classifies images into 1000 object categories, including many animals. It is trained on ImageNet, a large visual database designed for use in visual object recognition software research.
Yes, it’s been nearly five years since this example was published. However, the problem persists – various AI systems are far from fault-proof, even if advancements are done at supersonic speed.
Why is it so important for a certain AI system to differentiate between a panda and a gibbon? Well, companies are desperately looking for any opportunity to introduce AI systems into their business processes.
Sometimes it’s just so that they could eventually save money by reducing headcount, sometimes to relieve their human professionals of mundane tasks. No matter the reason, AI systems will become a crucial part of our lives – relied on to see whether a person is eligible for a loan, to “read” the road for autonomous vehicles, even to diagnose human illnesses.
Imagine an AI system concluding with certainty that a patient's mole is benign when it is, in fact, malignant. Or denying someone a loan because they’re a person of colour. Or someone fooling a car into mistaking a stop sign for a speed limit sign. When lives are at stake, we need to ensure that AI systems are 100% fault-proof.