Tech
European messaging apps enjoy a revival amid sovereignty push
European messaging apps, which market themselves as anonymity-focused alternatives to WhatsApp and Signal, are reporting increasing interest amid the continent’s efforts to break away from US tech.
Read more about European messaging apps enjoy a revival amid sovereignty push

Microsoft increases Xbox prices again: “Never thought I'd see the day video games become an investment”
Microsoft is increasing the price of the Xbox for the third time since last year, and there’s no end in sight.
Read more about Microsoft increases Xbox prices again: “Never thought I'd see the day video games become an investment”

Microsoft extends Windows 10 update program as users refuse to upgrade
Some users are avoiding the Windows 11 update like the plague and cite numerous reasons why it isn’t actually necessary.
Read more about Microsoft extends Windows 10 update program as users refuse to upgrade

Cookie banners were on the way out, but France and Germany stepped in
The European Commission has been trying to get rid of cookie banners for a long time. Thanks to the Digital Omnibus, the abolition of these banners was at hand. However, a few EU member states are now standing in the way of accomplishing this.
Read more about Cookie banners were on the way out, but France and Germany stepped in

EU proposes police cloud and €3bn for Europol
The European Commission wants to strengthen Europol and Eurojust by providing them with new means to combat cross-border crime and terrorism.
Read more about EU proposes police cloud and €3bn for Europol

Apple raises Mac and iPad prices as chip shortage drives up costs
Apple has raised prices of its iPad and MacBook line-up, saying it can no longer absorb surging memory and storage chip costs driven by the AI data centre boom, marking a rare move that shows even the world’s most valuable consumer tech company is feeling pressure from a global supply squeeze reshaping the PC and smartphone industry.
Read more about Apple raises Mac and iPad prices as chip shortage drives up costs
EU plans stricter rules for Amazon and Microsoft cloud services to ease switching between providers
EU antitrust regulators said Amazon and Microsoft's cloud computing services should be designated as “gatekeepers” under landmark tech rules, a step that would subject them to strict obligations aimed at curbing market power.
Read more about EU plans stricter rules for Amazon and Microsoft cloud services to ease switching between providers

Fake Apple Watches at Target: what happened and how to respond
There’s a reason why you might want to unbox your Apple Watch or AirPods while you’re still at the counter.
Read more about Fake Apple Watches at Target: what happened and how to respond

What sovereignty? Internet traffic of millions of Europeans flows through Chinese routers
Despite Europe stepping up its efforts to achieve its digital sovereignty, most of the continent’s internet traffic flows through Chinese-made routers, putting Europeans at risk of cyber espionage.
Read more about What sovereignty? Internet traffic of millions of Europeans flows through Chinese routers

Samsung thinks a 7-year-old TV might be too old, but users disagree
Samsung says you might be missing out on features that come with a new TV, but users are pushing back: “Where am I supposed to put a perfectly fine TV?”
Read more about Samsung thinks a 7-year-old TV might be too old, but users disagree
What is fearmaxxing? Experts question the self-improvement trend
Fearmaxxing, a viral self-improvement trend that encourages people to confront their biggest fears, is gaining traction online, but experts warn that treating fear as a universal signal for action can lead to impulsive decisions and costly mistakes.
Read more about What is fearmaxxing? Experts question the self-improvement trend
Windows hibernation may contribute to SSD wear as storage costs rise
Experts are warning that a common Windows feature – hibernation – could be quietly increasing wear on SSDs, at a time when storage prices are rising sharply, and replacements are becoming significantly more expensive.
Read more about Windows hibernation may contribute to SSD wear as storage costs rise
Digital euro gains support as Europe seeks payment independence from the US
The European Central Bank secured key parliamentary backing on Tuesday for the launch of a digital euro, an electronic means of payments aimed at making the euro zone less reliant on US credit cards at a time of fraying transatlantic relationships.
Read more about Digital euro gains support as Europe seeks payment independence from the US

Tensions brew over use of Palantir software in Germany
A coalition party in the state of North Rhine-Westphalia wants law enforcement to ditch Palantir’s software, sparking tensions within the ruling coalition.
Read more about Tensions brew over use of Palantir software in Germany

Microsoft confirms Recycle Bin bug in Windows 10 and 11: a patch is on the way
Microsoft has acknowledged that a new Windows bug is causing issues with the desktop Recycle Bin. The Redmond-based tech company is currently working on a patch to fix the issue.
Read more about Microsoft confirms Recycle Bin bug in Windows 10 and 11: a patch is on the way
Bankruptcy, trademark wars, and digital detox: How did Commodore live through it all?
Commodore’s new retro flip phone, the Callback 8020, is actually a product of a company with a 70-year history.
Read more about Bankruptcy, trademark wars, and digital detox: How did Commodore live through it all?

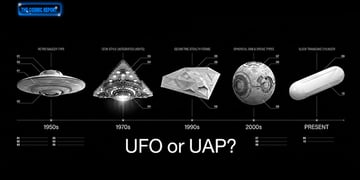
Spielberg on the “UFO” term, Loeb on humans as probes, and SpaceX shares wobble
This week, The Cosmic Report rounds up Steven Spielberg's insistence on using the “UFO” lexicon, an Avi Loeb talk on humans as probes for aliens, and pivots to SpaceX’s first week on the stock exchange.
Read more about Spielberg on the “UFO” term, Loeb on humans as probes, and SpaceX shares wobble
Have you experienced any of these Android 17 bugs?
Just a few days after rolling out Android 17, users are already reporting issues, including unresponsive WiFi connections and missing widgets.
Read more about Have you experienced any of these Android 17 bugs?

Durov loses court challenge as India upholds temporary Telegram ban over exam leak
Telegram on Friday lost its bid to overturn an Indian government order temporarily banning the messaging app, with a New Delhi court ruling that the government's actions, aimed at preserving the integrity of a key med school exam, were legal and reasonable.
Read more about Durov loses court challenge as India upholds temporary Telegram ban over exam leak

Germany would rather accept weaker cloud services than depend on US providers
German companies are increasingly concerned about being overreliant on American tech. The latest figures show that a growing number of businesses would rather store their data on a national cloud system and even compromise some services and lower prices to avoid providers from abroad, particularly the US.
Read more about Germany would rather accept weaker cloud services than depend on US providers
